設計者の1案件 50〜340分 の図面照合が、約10分 に圧縮された。
2026-02-19、パナソニックコネクトが社内AI基盤 ConnectAI 上で展開した Manufacturing AIエージェント の成果だ。削減率は 最大97% (公式プレスリリース)。プレスを真面目に読み込むと、削減幅は案件によって 80〜97% で振れる。50分→10分なら80%、340分→10分なら97%。一律「97%削減」と煽る他媒体に乗らず、まずこの幅を押さえておきたい。
中身は Snowflake データクラウドと Snowflake Cortex AI。「大企業の話」で終わらせず、Snowflakeを持たない中小製造業がどうやって同じ思想を自前で動かすか を、本稿は50行のPythonコードまで分解する。

- 30秒でわかる: 2026-02-19、パナソニックが本当に発表したこと
- なぜ図面照合は50〜340分もかかるのか — 4つの構造的理由
- Manufacturing AIエージェントの中身 — Snowflake Cortex AIで動いているもの
- 中小製造業がSnowflake不要で同じことをやる現実解
- 【実装コード】PDF図面2枚を照合してExcelレポート化する50行
- タナカ部長の壁 — 「で、うちの誰が書くの?」問題
- 社員教育まで考えるなら — Claudeを社員全員が触れる組織を作る
- ROI試算 — 月100件の照合なら何か月で元が取れるか
- 失敗パターン6選 — Claude APIで図面照合を組むときのハマりどころ
- まとめ: 97%削減は「パナソニックだから」ではない
- ソースコード / 出典
30秒でわかる: 2026-02-19、パナソニックが本当に発表したこと
3行で要点を出す。
- パナソニックコネクトが 設計・開発部門の図面照合 を Manufacturing AIエージェントで自動化
- 1案件あたり 50〜340分 → 約10分 (最大97%削減)
- 動かしているのは社内AI基盤 ConnectAI 上で動く Snowflake Cortex AI
ConnectAI 全体の数字も並べておく。社内利用者 約11,600人、2025年の年間削減時間は 44.8万時間 (パナソニックコネクト公式 / monoist 2026-02-25)。1タスクあたり平均削減は 約20分 だ。
| 数字 | 値 | 出典 |
|---|---|---|
| 図面照合の削減率 | 最大97% (幅: 80〜97%) | パナソニックコネクト 2026-02-19 |
| 削減前工数 | 50〜340分/件 | 同上 |
| 削減後工数 | 約10分/件 | 同上 |
| ConnectAI 社内利用者 | 約11,600人 | 同上 |
| ConnectAI 年間削減時間 (2025) | 44.8万時間 | 同上 |
| 発表日 | 2026年2月19日 | 同上 |
「最大97%」を冒頭で出すのは正しい。ただし幅で書かないと現場が信用しない。50分の案件と340分の案件では、現場の痛みも、削減後の体感もまったく違う。
なぜ図面照合は50〜340分もかかるのか — 4つの構造的理由
「目視で照合するだけで340分?」と疑う読者もいる。答えは、製造業の設計レビューが情報照合の塊 だからだ。
理由1: 照合項目が数十〜数百ある
1枚の図面に 材質・仕上げ・公差・記号・規格番号・熱処理・寸法・表面粗さ が散在する。製品図面 × 部品図面 × 技術仕様書を横並びで突き合わせるので、項目数は掛け算で膨らむ。
理由2: 用語が標準化されていない
同じ材質でも「SUS304」「SS304」「ステンレス304」と書く人がいる。アルマイトは「アルマイト処理」「陽極酸化」と表記揺れする。表記揺れの突合は人間が一番苦手な作業 だ。
理由3: 1案件に3〜5文書が絡む
平面図、詳細図、部品図、技術仕様書、社内規格書 — 1案件で平均3〜5文書を行き来する。「どの図面のどの欄が正なのか」が分かるのはベテランだけ、という属人化が必ず発生する。
理由4: 後工程で見つかると手戻りが数十倍に膨らむ
照合漏れが設計段階で見つかれば修正は10分。後工程 (試作・量産) で発覚すると数十〜数百倍 のコストになる。だから設計者は前工程で時間をかける。50〜340分はサボっているのではなく、手戻りコストを織り込んだ合理的な投資 なのだ。

ここを丸ごとAIに渡せれば、削減幅は自然と大きくなる。340分案件で97%削減になる理由は「大規模案件ほどルーティン照合の比率が高い」点にある。
Manufacturing AIエージェントの中身 — Snowflake Cortex AIで動いているもの
公式情報から確実に読み取れる構成は次の通り。
| レイヤ | 採用技術 | 役割 |
|---|---|---|
| データ基盤 | Snowflake データクラウド | PDF含む非構造化データの取り込み・保持 |
| LLM/AI機能 | Snowflake Cortex AI (LLM関数群) | テキスト抽出・項目照合・結果生成 |
| 入力 | 複数PDF図面 + 技術仕様書 | 製品図面/部品図面/仕様書のセット |
| 出力 | 照合結果一覧 (項目別 OK/NG) | 設計者の確認作業を支援 |
| 上位基盤 | ConnectAI (社内AIプラットフォーム) | 約11,600人の社員向け基盤 |
| 開発体制 | 内製 | 外注パッケージではない |
Cortex AIには EXTRACT_ANSWER / COMPLETE / SUMMARIZE といったLLM関数があり、SQLからLLMを呼べる のが特徴だ。データを動かさずにSnowflake上で構造化・照合まで完結する。GPU管理もモデルホスティングも不要。
ここで重要なのは、Snowflake Cortex AIの本質は「PDF抽出 → LLM構造化 → 突合判定」のパイプラインを内製したこと にある。Cortexは部品の1つでしかない。中小製造業にとっての示唆は、Snowflakeのライセンス費ではなく 「このパイプラインの設計思想」 のほうだ。
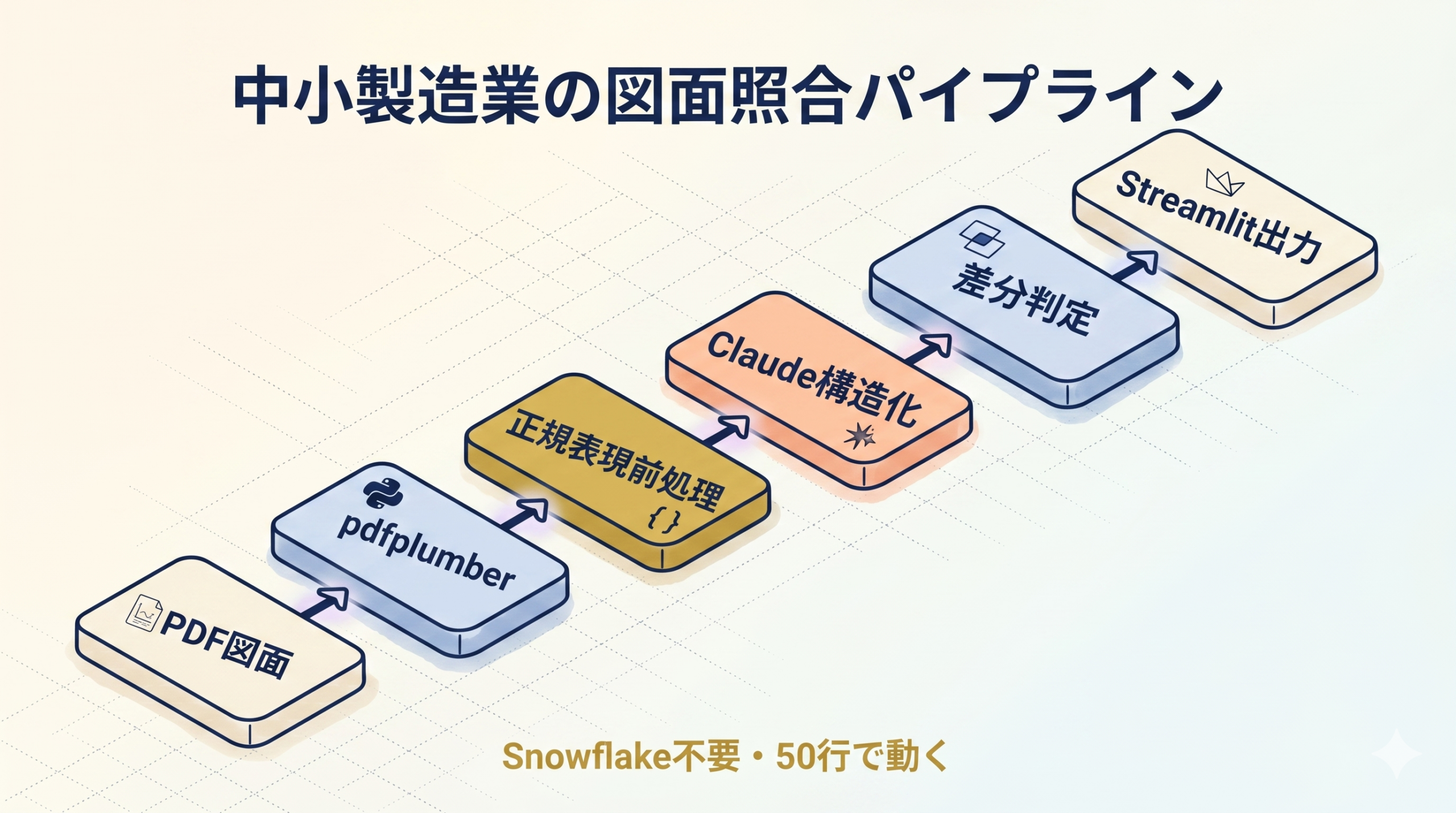
中小製造業がSnowflake不要で同じことをやる現実解
Snowflake Cortexは便利だが、中小製造業がいきなり契約するのは現実的ではない。月額契約・データ移行・社内承認 のハードルが高すぎる。
代わりに、同じ思想をOSSと従量課金のClaude API で組む。
[PDF図面群]
↓
[Step 1] pdfplumber / PyMuPDF で生テキスト + 表構造を抽出
↓
[Step 2] 正規表現で確実なフィールド (材質コード/寸法/規格番号) を先抽出
↓
[Step 3] Claude Sonnet 4.6 API で構造化JSON化 (cache_control 有効)
↓
[Step 4] 別図面/仕様書も同じJSON構造で抽出
↓
[Step 5] Claude に2 JSONを渡して「項目別の差分」を判定
↓
[Step 6] Streamlit で OK/NG/要確認 を色分け表示 → Excel出力採用技術はすべて従量課金 or 無料で揃う。
| レイヤ | 推奨技術 | 月額固定費 |
|---|---|---|
| PDF抽出 | pdfplumber / PyMuPDF | ¥0 (OSS) |
| 正規表現前処理 | Python標準 re |
¥0 |
| LLM構造化 | Claude Sonnet 4.6 ($3/$15 per 1M tokens) | 従量のみ |
| LLM照合 | Claude Sonnet 4.6 (or Haiku 4.5: $1/$5) | 従量のみ |
| UI | Streamlit | ¥0 (OSS) |
| プロンプトキャッシング | Anthropic公式 (入力90%割引) | 従量のみ |
想定値: 1案件あたり入力20K + 出力5Kトークンで 約¥21/案件 (1ドル150円換算)。キャッシュとバッチを併用すれば約¥6/案件 まで落ちる。月100件処理しても 約¥600〜¥2,100/月 の世界だ。
【実装コード】PDF図面2枚を照合してExcelレポート化する50行
ここから実装に入る。コードは GitHub に全文公開する (本稿末尾リンク)。本文では中核の Claude構造化呼び出し部 だけを抜粋する。
中心となるのは pipeline.py の extract_with_claude 関数。プロンプトキャッシング と Pydantic型ガード が2つの肝だ。
from anthropic import Anthropic
from pydantic import BaseModel
from prompts import SYSTEM_PROMPT, EXTRACTION_USER_PROMPT, normalize_term
MODEL_ID = "claude-sonnet-4-5" # = Sonnet 4.6 (公式モデルID)
def extract_with_claude(raw_text: str) -> DrawingDoc:
"""PDFテキストをClaudeに渡し、構造化JSONで戻す。"""
client = Anthropic()
msg = client.messages.create(
model=MODEL_ID,
max_tokens=1024,
system=[{
"type": "text",
"text": SYSTEM_PROMPT,
# ★ システムプロンプトと表記揺れ辞書をキャッシュ (入力90%割引)
"cache_control": {"type": "ephemeral"},
}],
messages=[{
"role": "user",
"content": EXTRACTION_USER_PROMPT.format(raw_text=raw_text[:8000]),
}],
)
payload = _parse_json(msg.content[0].text)
# ★ Claudeが取りこぼしても、Python側で表記揺れを正規化し直す二重防衛
if payload.get("material", {}).get("value"):
payload["material"]["value"] = normalize_term(
payload["material"]["value"], "material"
)
return DrawingDoc(**payload) # ★ Pydanticで型ガード (壊れたJSONはここで弾く)ポイントは3つ。
1. cache_control: ephemeral で入力料金が90%引き システムプロンプトに表記揺れ辞書 (SUS304 ≡ ステンレス304 ≡ SS304 …) を載せると最低1,024トークンを超えるので、キャッシュが効く。2案件目以降は入力料金が10分の1になる。
2. Python側で normalize_term を再度かける二重防衛 LLMが「ステンレス304」を正規形に直し忘れても、辞書ベースで SUS304 に寄せる。LLMの揺れに業務判定を依存させない のがコツ。
3. Pydantic DrawingDoc で型ガード Claudeが稀に返す壊れたJSONをここで弾く。material.value / material.evidence が必須項目として保証されるので、下流の差分判定が安定する。
これだけで「PDF → 構造化JSON」が動く。差分判定は match_documents 関数 (同じくシステムプロンプトをキャッシュ + JSONを2件Claudeに渡す) で完結し、結果は pandas.DataFrame で返る。
Streamlit側 (app.py) は2ファイルアップロード → run_pipeline() を呼ぶだけ。OK/NG/要確認 を色分けして表示し、Excelダウンロードボタンを追加して合計89行で完結している。
タナカ部長の壁 — 「で、うちの誰が書くの?」問題
ここまで読んで「うちでも組めそう」と思ったとして、現場でぶつかる壁は技術ではない。人材 だ。
中堅精密板金メーカー (従業員80人) の設計部長 タナカ部長 (52歳) は、パナソニックの発表記事を見てこう言った。「うちもやりたい。でも書けるやつが社内にいない」。若手の ヨシダさん (29歳) はPythonをちょっと触ったことがあり、ChatGPTを個人で使っているレベル。Claude Codeのセットアップから始めるとして、業務知識をプロンプトに落とし込めるかは別問題だ。
別の鋳造メーカー (従業員150人) の経営者 ヤマモト常務 (60歳) はもっとシビアだ。「で、いくらで、誰がやってくれるの? うちには書ける人いないけど」。
中小製造業の現実は次の3パターンに収束する。
- 「やりたい」で止まる — 記事を見て社内で話題になるが、誰も書き始めない
- 「ChatGPTで」が分散する — 社員ごとに使い方がバラバラ、業務知識は蓄積されない
- 「外注に丸投げ」で見積もり300万円 — 中小には払えない、結局塩漬け
RIETIコラム (2025) によれば、中小企業の生成AI導入率は約5% (大企業は約20%)。「導入を検討中」が46.2%もあるのに、実装に踏み出せない理由の中核が人材 だ (経産省ものづくり白書2025、デジタル人材の確保は約6割が「社内人材活用・育成」で済ませようとしている)。
ここで本稿が一番伝えたいのは、「コードが書ける」と「業務AIを社内で回せる」は別スキル だということだ。Claude Codeでコードを書く技術はAIに任せられるが、「自社の図面照合の業務固有ルール」 をどうプロンプトと辞書に落とすか は経営者と現場が一緒に設計する仕事になる。
経営者がこの設計に伴走する仕組みが必要なら、AI鬼管理 のような 経営者向け1対1伴走プログラム が現実解になる。Claude Codeの導入から、図面照合のような業務固有タスクをAIエージェント化するノウハウ提供まで、90日伴走で社内に「回せる組織」を作る設計だ。中小製造業の「人材ゼロ・予算限定」を前提に組まれている点が、汎用研修と決定的に違う。
社員教育まで考えるなら — Claudeを社員全員が触れる組織を作る
経営者の伴走と並行して走らせたいのが 社員のスキル底上げ だ。
タナカ部長が伴走支援で組織設計の絵を描いても、現場のヨシダさんが Claude を触れなければ運用は回らない。ここで補助CTAとして機能するのが DMM 生成AI CAMP のような 社員向けスクール型学習 だ。
| 観点 | AI鬼管理 (伴走) | DMM 生成AI CAMP (スクール) |
|---|---|---|
| 対象 | 経営者・部長クラス | 現場社員・若手 |
| 目的 | 組織として回す設計 | 個人がツールを使えるようになる |
| 期間 | 90日伴走 | 数週間〜数ヶ月のカリキュラム |
| 中小製造業との相性 | 「誰もやらない」を突破 | 「全員バラバラ」を統一 |
この2つは競合ではなく 役割が違うので併用可能 だ。経営者が伴走で組織を設計し、その下で社員がスクールで個人スキルを底上げする — 二段構えで進めれば、ヨシダさんが pdfplumber + Claude のコードを自分の手でデプロイできる状態にたどり着く。
ROI試算 — 月100件の照合なら何か月で元が取れるか
実数で詰める。想定値ベースの試算だ。
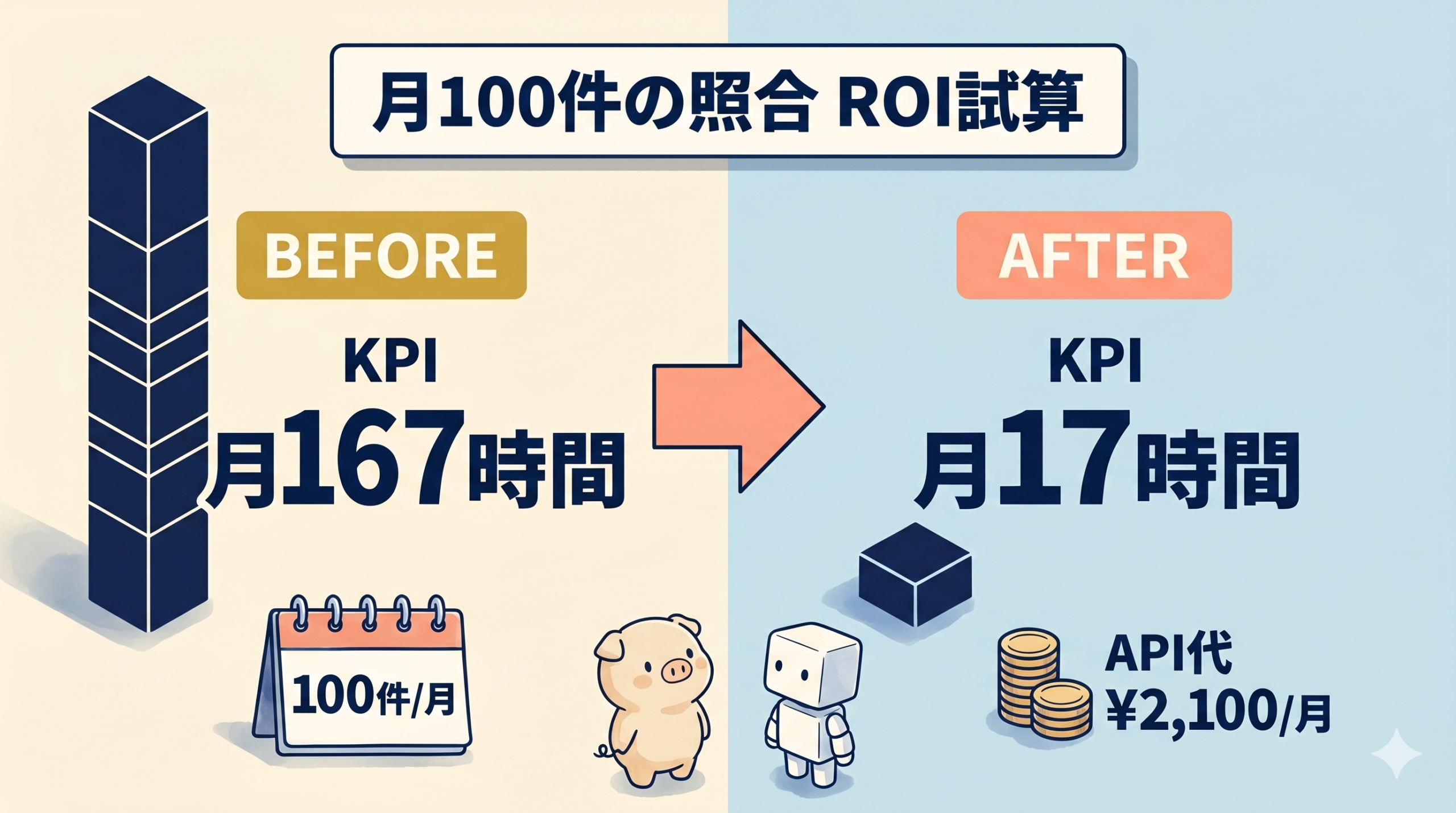
想定値: 中小製造業の設計部門 (10人規模) で図面照合が月100件発生。1件あたり平均90分 (50〜340分の中央値寄り) で照合しているとする。
| 項目 | 現状 | AI導入後 (想定値) |
|---|---|---|
| 1件あたり工数 | 90分 | 10分 (約89%削減) |
| 月間100件の総工数 | 150時間/月 | 16.7時間/月 |
| 削減時間 | — | 約133時間/月 |
| 設計者の時給換算 (¥4,000) | ¥600,000相当/月 | ¥66,800相当/月 |
| Claude API費 (キャッシュ有) | ¥0 | 約¥600〜¥2,100/月 |
| 月次差額 | — | 約¥530,000の余力創出 |
想定値ベースなので「キッカリこの数字になる」とは言えない。ただ、APIコストは月の人件費1人分にはるかに届かない という構造は普遍だ。月100件規模なら初月から黒字 で回り、削減した133時間は新規受注のレビューや改善活動に振り向けられる。

注意したいのは「削減した時間を 何に振り向けるか を先に決めないと、結局元の業務が膨張して埋め戻される」点だ。AI導入は時間を作る話ではなく、時間の使い道を再設計する話 だ。
失敗パターン6選 — Claude APIで図面照合を組むときのハマりどころ
実装に踏み出すなら、先にこの6つを知っておきたい。
1. PDF図面のテキストが取れない (CADから出力された図面) pdfplumberで空文字が返ってくることがある。CAD出力時にテキストが線分化されていると発生する。対策: PyMuPDFで再試行、それでもダメなら Claude Vision (画像入力) or Tesseract OCR。
2. 表記揺れ辞書が必須 「SUS304」「ステンレス304」「SS304」を同義語登録しないと、整合性NG誤判定が連発する。辞書をシステムプロンプトに載せ、Python側でも normalize_term() を二重に走らせる のがコツ。
3. Claude APIのPDFサイズ制限 (32MBまで) A1図面など大判は分割が必要。pdfplumber で1ページずつ処理し、結果のJSONを後段でマージする実装が安全。
4. プロンプトキャッシング有効化忘れ → 料金10倍 cache_control: {"type": "ephemeral"} を system に付与しないと、毎回フル課金される。システムプロンプトと辞書を必ずキャッシュ対象 にする。
5. 「OK/NG」だけだと現場が信用しない 判定結果に evidence (どの文字列を根拠にしたか) を必ず含める。Pydantic の Field2 で value / evidence をペアで扱う設計にしておくと、後から「なぜNG?」を辿れる。
6. Streamlitファイルアップロードが詰まる デフォルト200MB上限。複数PDFを束ねるとぶつかる。.streamlit/config.toml で server.maxUploadSize = 500 に上げておく。
まとめ: 97%削減は「パナソニックだから」ではない
最後にもう一度、構造を整理する。
| 観点 | パナソニック版 | 中小製造業版 (本稿の提案) |
|---|---|---|
| データ基盤 | Snowflake データクラウド | ローカルディスク + Streamlit |
| LLM | Snowflake Cortex AI | Claude Sonnet 4.6 (API直叩き) |
| UI | ConnectAI 統合画面 | Streamlit (89行) |
| 開発体制 | 内製 + Snowflakeパートナー | 社内 + 経営伴走 (任意) |
| 月額固定費 | Snowflake利用料 | ¥0 (従量のみ) |
| 1件あたりコスト | 非公開 | 想定値 約¥6〜¥21 |
| 削減率 | 最大97% (幅 80〜97%) | 思想は同じ、規模は案件次第 |
97%削減は技術的に特別なことをしているわけではない。PDF抽出 → LLM構造化 → 突合判定 という、教科書的なパイプラインを 「業務知識を辞書化して、表記揺れに耐える形で」 組み上げただけだ。
中小製造業がこれをやれない理由は、技術ではなく 誰が業務知識を辞書とプロンプトに落とすか で詰まっている。コードはAIに書かせられる時代になった。だからこそ、業務固有の判定ロジックを設計する人 が、いま一番の希少資源だ。
「うちでもやりたい」で止まらないために、次の一歩を1つだけ選ぼう。
- 今すぐ動かす: GitHub のサンプルを clone →
--dry-runでモック動作確認 → 自社の図面PDFで試す - 組織として回す: 経営者向け伴走 (AI鬼管理) で90日の社内展開設計を組む
- 現場のスキル底上げ: 社員教育 (DMM 生成AI CAMP) で全員がClaudeを触れる状態を作る
ソースコード / 出典
- GitHub:
panasonic_drawing_match/(本稿の50行実装 + Streamlit UI + サンプル生成スクリプト一式) - パナソニックコネクト プレスリリース 2026-02-19「Manufacturing AIエージェントの社内展開について」
- monoist (ITmedia) 2026-02-25 取材記事
- RIETIコラム 2025「中小企業における生成AI導入の現状」
- 経産省 ものづくり白書 2025
- Anthropic公式ドキュメント (Prompt Caching / Sonnet 4.6 / Pydantic連携)
🥷 Claude Code を本気で社内導入するなら
「自社の業務を Claude Code で自動化したいが何から手をつけるか分からない」中小製造業向けの伴走型トレーニング AI鬼管理。無料の業務効率化診断 (オンライン面談) で、自社のどこから自動化できるかが見える化される。
▶ AI鬼管理 | Claude Code活用の業務自動化トレーニング 無料診断を予約する
※公式LINE経由でも申込可・診断のみで無理な勧誘なし
🎯 ChatGPT/Claude/Geminiを社内で使いこなすなら
ChatGPT・Claude・Gemini・Copilot・Difyを横断的に学べる「学び放題」が、現場での再現性が一番高いと感じています。月額¥14,800・縛り無し・合わなければ翌月解約OK。
期間限定:豪華7大特典つきキャンペーン中
▶ 月額16,280円で生成AIを好きなだけ学べる!「DMM 生成AI CAMP 学び放題」
![]()
※「合わない」と感じたらマイページから翌月解約OK・しつこい勧誘なし


コメント