2026年5月14日、経産省とNEDOがGENIAC第4期の採択11件を発表した。製造業データのAI-Ready化9件、ロボット基盤モデル2件。1件あたり最大5億円、100%委託、応募36件からの選抜。
注目すべきは中身の構図だ。テキスト・図面の暗黙知をストックマーク+国内16社、動画・骨格・視線の暗黙知をFastLabel+大手自動車OEM。日本の暗黙知データ化が、文字側と身体側の2陣営で同時に国家予算化された瞬間だった。
本記事は、この2陣営マップを一次プレス横断で整理したうえで、中小製造業がGENIACを待たずに「スマホ+MediaPipe+LLM」で5万円ミニマム版を今日から始めるための具体手順までを通しでまとめる。

H2-1. 5月14日、経産省が動いた ── GENIAC第4期で起きたこと
GENIAC(Generative AI Accelerator Challenge)は2024年2月に経産省・NEDOが発足させた生成AI開発支援枠だ。第1〜3期までは基盤モデル開発の計算資源支援が主軸だった。2026年度から新規枠として(a)製造業データのAI-Ready化、(b)ロボット基盤モデル開発が追加された。
第4期の数字を整理する。
| 区分 | 採択数 | 形態 | 上限 | 期間 |
|---|---|---|---|---|
| 製造業データAI-Ready化 | 9件(応募36件) | 委託(100% NEDO負担) | 1件最大5億円 | 2026〜2027のうち1年 |
| ロボット基盤モデル | 2件 | 助成 | — | 2026〜原則1年 |
製造業AI-Ready化9件のうち、現時点で一次プレス・PRTIMESで確認できた採択者は以下の3者。
| 採択者 | テーマ方向性 | パートナー |
|---|---|---|
| FastLabel | 暗黙知の構造化データ化 + 業界汎用性検証 | 国内大手自動車OEM |
| ストックマーク | 図面・社内データ・匠の知のAI-Ready化 | 国内16社(味の素/伊藤忠/スズキ/三井住友/三菱ケミカル/住友化学/ジェイテクト等) |
| フツパー | 製造業データAI-Ready化基盤(画像系) | — |
上位政策はもう1段大きい。日本経済新聞2025-12-19報道によれば、政府はフィジカルAI支援に5年で1兆円、2026年度予算で3,000億円を計上する方針。GENIAC第4期はその先頭に置かれた実弾だ。
ここで効いているのがFastLabelの位置取りだ。9件のうち、動画・骨格・視線という「身体動作の暗黙知」をやるのはFastLabelが唯一。フィジカルAIのデータ層に直結する。
H2-2. 「暗黙知のフィジカルAI化」を分解する
FastLabelの採択テーマ正式名は長い。「生産技能者が保有する暗黙知の構造データ化技術開発とその業界汎用性に関する研究開発」。連携先は国内大手自動車OEM(社名非公表)。
中で何をやるかを分解すると、構造はシンプルだ。
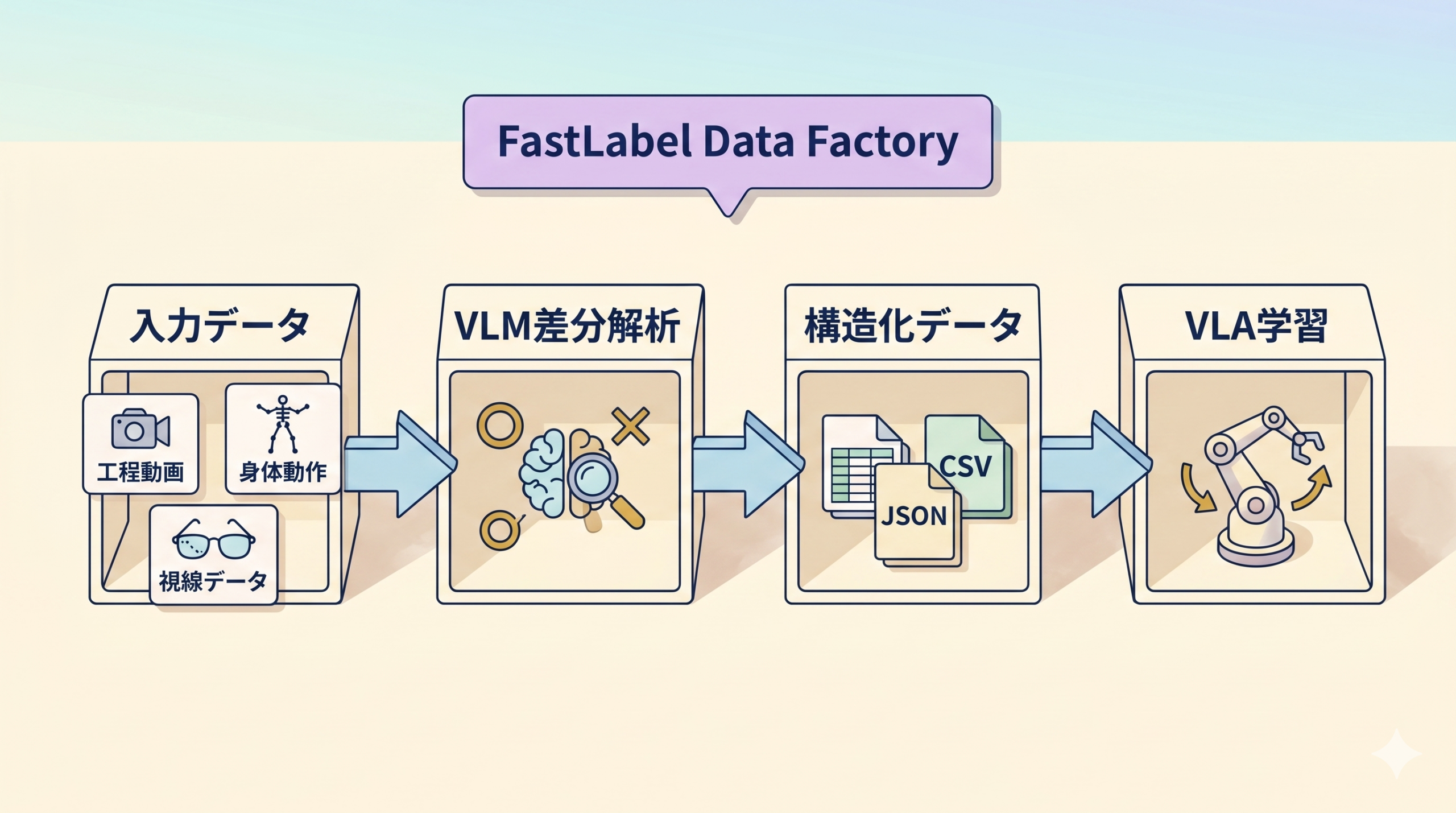
1. 集める素材
- 工程作業動画(一人称視点 + 三人称視点)
- 骨格モーションデータ(関節角度・手先軌跡)
- 視線データ(eye-gaze / アイトラッキング)
2. 処理パイプライン
- FastLabel Data Factoryでマルチモーダルアノテーション
- VLM(Vision Language Model)+ 差分解析で「うまくいった/いかなかった」の違いを自動検出
- 「経験的判断」「微細な動作調整」を再現可能な構造化データへ変換
- フィジカルAI(VLA: Vision-Language-Actionモデル)学習用フォーマットで提供
3. アウトプット
- 一人称視点データ取得〜構造化までのソリューションパッケージ
- 業界汎用テンプレート(横展開用)
- 遂行主体は2026年4月設立の Robotics AI事業部(R&Dセンターは2025-10-15に先行設立済)
なぜこの筋がいいか。VLAモデル(Pi-0、Helix-02、Figure 02系)は実世界マルチモーダルデータを大量に要求する。海外で標準的に使われるOXEデータセット(22ロボット527スキル)には、日本工場の「擦り合わせ」「面取り」「微細調整」がほぼ含まれない。ここを日本側のデータで埋めない限り、海外基盤モデルは日本の現場では動かない。
同じ発想で、米Scale AIは「Data Engine for Physical AI」を展開しており、2026-01にMetaが150億ドルを投じた。フィジカルAIの主戦場はモデルではなくデータ層という認識が、日米同時にコンセンサスになりつつある。
H2-3. なぜ国家プロジェクトになったか ── 技能伝承の構造危機
事業として筋がいいだけでは国家予算は降りない。背景にあるのは技能伝承の構造危機で、数字は厚労省・経産省側でほぼ揃っている。
| 数字 | 値 | 出典 |
|---|---|---|
| 製造業就業者推移 | 1,055万人 → 1,046万人(-9万人) | ものづくり白書2025(2025-05閣議決定) |
| 製造業「技能伝承を経営課題視」 | 59.5%(15業種中3位) | ものづくり白書2025 |
| 製造業事業所「指導者不足」 | 61.8% | 2024年厚労省 能力開発基本調査(最新版) |
| 将来の技能継承に不安 | 約80% | 労働政策研究機構(2024年度) |
特に厚労省の61.8%は、製造業事業所のうち「指導する人材が不足している」と回答した割合で、これは2024年6月公表の能力開発基本調査(調査時点としてはこれが最新版)に拠る。製造業事業所の6割超が「教える人がいない」と答えている状態を、AI/データ側で吸収しに行く、というのがGENIAC第4期の建付けだ。
FastLabelが採択された背景も、この文脈で読むと素直に説明がつく。
- GENIAC第2期でNABLAS、リコーマルチモーダルLLM等の支援実績あり
- アノテーション代行国内最大級(100社・10,000ラベル超、画像1枚2円〜、品質99.7%)
- 動画オブジェクトトラッキング自動化を商用化済
- 2026年4月にRobotics AI事業部新設で、ロボット領域の専門体制を整備済
「データの量・速度・品質」を担保できる国内事業者が、たまたまフィジカルAIの新枠と噛み合った形だ。
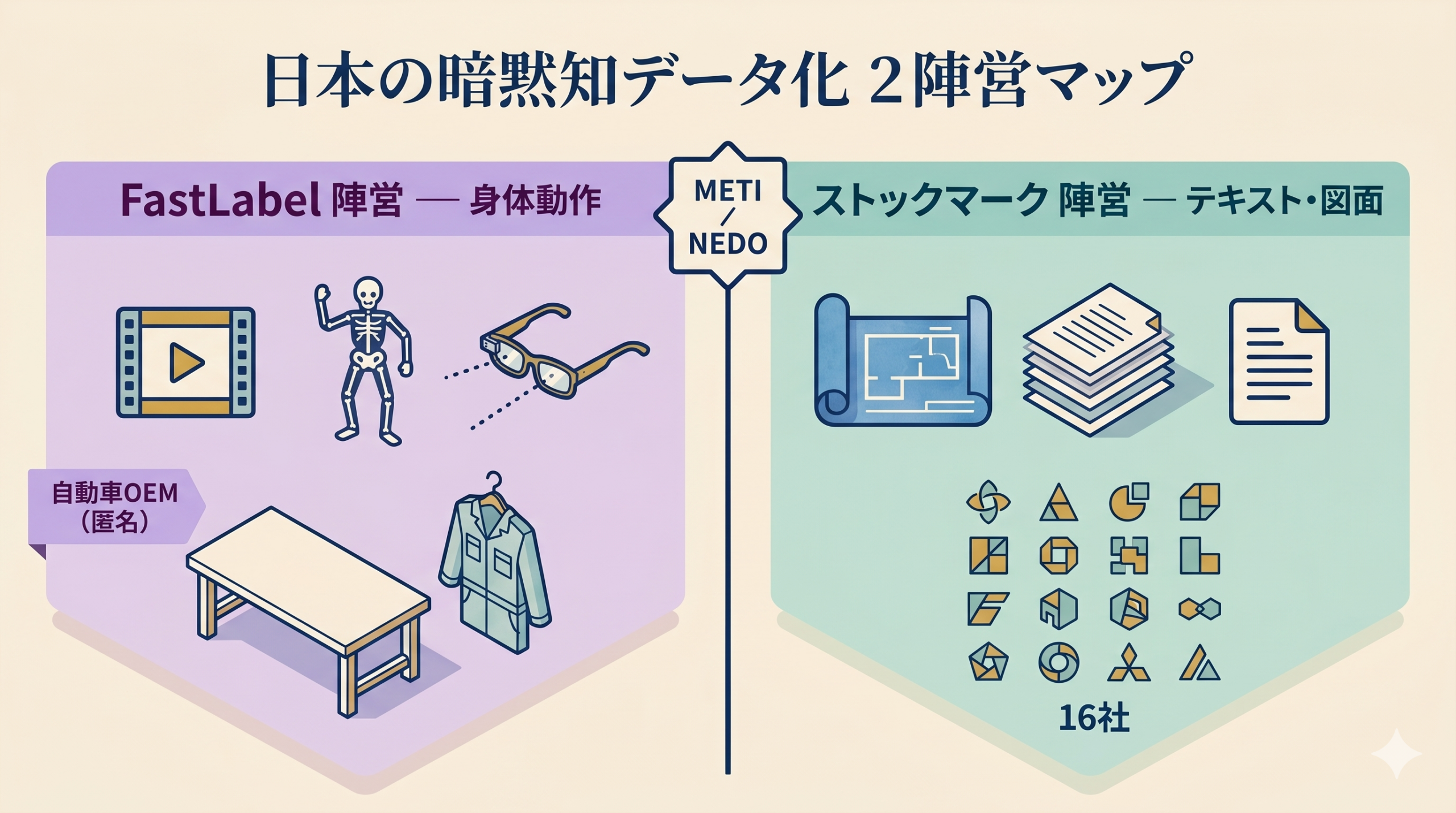
H2-4. もう一つの陣営 ── ストックマーク16社が示す「テキスト系暗黙知」
ここでもう一方の陣営を見る。同期採択のストックマーク主導案件は、構成も狙いもFastLabelとは綺麗に対になっている。
参画企業16社(2026-05-14 PRTIMES)は、味の素・伊藤忠商事・スズキ・三井住友銀行・三菱ケミカル・住友化学・ジェイテクト等。化学・素材・自動車・商社・金融が混ざる超業種混成コンソーシアムで、PoC期間は2026年5月〜10月に集中する。
ストックマーク陣営が扱うのはテキスト/図面/社内文書/熟練者へのインタビュー記録だ。CADの注記、品質管理基準書、改善提案レポート、ベテランがメモ用紙に走り書きしたノウハウ。こちらは「言語化された/されかけている暗黙知」を、LLM学習用に構造化していく方向。
一方FastLabel陣営が扱うのは動画/骨格/視線だ。言語化される前の身体動作そのものを、VLM/VLAで構造化する方向。
2陣営の役割分担を整理するとこうなる。
| 軸 | ストックマーク陣営 | FastLabel陣営 |
|---|---|---|
| 扱うデータ | テキスト・図面・文書 | 動画・骨格・視線 |
| 言語化の度合い | 言語化済み or しかけ | 言語化前(身体動作) |
| 出力先モデル | LLM(テキスト基盤) | VLA(Vision-Language-Action) |
| パートナー | 国内16社(化学/素材/自動車/商社) | 国内大手自動車OEM(1社) |
| 想定ユースケース | 設計判断・改善提案・品質管理 | 組立・擦り合わせ・面取り |
| 主戦場の競合 | (国内)kubellSpark、ABEJA | (海外)Scale AI、Snorkel AI |
経産省がこの2軸を同時に押さえたという事実が、本件最大のメッセージだ。テキストか身体動作か、どちらか片方ではフィジカルAI時代の暗黙知は抜けない。両方を国内事業者で押さえに行く構図が、政策側の意思として明確に出ている。
海外側のリアルを補足しておくと、Figure AIのFigure 02はBMWスパルタンブルク工場で11か月稼働、累計1,250時間、9万部品、3万台のX3生産に貢献した(Figure AI公式・2025〜2026)。VLAの実証は海外がリード。だからこそ、日本側はデータ層で勝負するしかない。
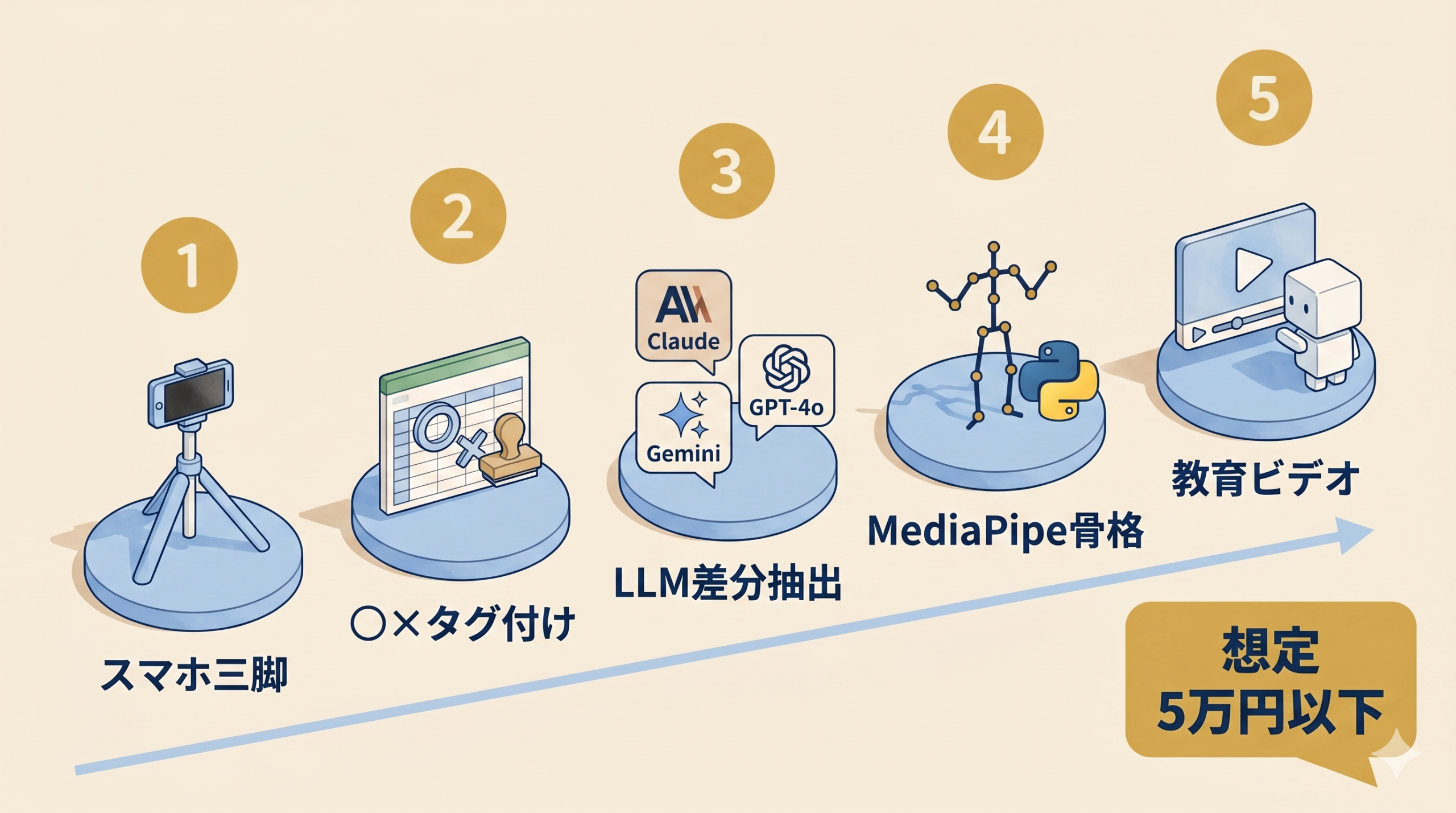
H2-5. 中小製造業がGENIACを待たずに今日始める5ステップ
ここからが本題だ。1件5億円の国家プロジェクトは中小製造業には直接降りてこない。だが、やっていることの構造は中小現場でも再現可能で、ミニマム版なら想定値5万円以下から始められる。
以下、Day単位で動ける手順に落とす。
Step 1: スマホ三脚で熟練工作業を撮る(Day 1-2)
- 一人称視点: GoPro or iPhoneを胸ポケット固定 or ネックマウント
- 三人称視点: 三脚を作業台の斜め前 45°
- 1工程あたり5〜10分 × 10本程度
- 撮影時にベテラン本人へ「成功した」「失敗した」を口頭で言ってもらう(後工程のラベル元)
Step 2: 「○/×」だけタグ付け(Day 3)
- Excel or Notionで動画ファイル名 + 結果(○/×)+ 一言コメント
- この段階で「なぜ○なのか」を書こうとしない。書ける部分はもう暗黙知ではない
Step 3: AIに動画を見せて「違い」を抽出(Day 4-7)
- Claude(sonnet系)、Gemini 2.5 Flash、GPT-4oの動画対応モデルへアップロード
- プロンプト例:「○と×の動画を比較し、手の位置・速度・順序の違いを箇条書きで」
- 同じ動画を複数のLLMに同時に投げて差分を取ると、単独LLMでは見逃す観点が浮く。DoraVerseのような複数LLM同時比較ツールを使うと、Claude / Gemini / GPT-4oの差を1画面で並列確認できる。
Step 4: 骨格抽出はMediaPipeで無料(Day 8-14)
Google製MediaPipe Poseを使えば、Python数十行で関節角度CSVが取れる。
import cv2
import mediapipe as mp
import csv
mp_pose = mp.solutions.pose
cap = cv2.VideoCapture("veteran_001.mp4")
with mp_pose.Pose(model_complexity=2) as pose, \
open("veteran_001.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["frame", "r_shoulder_y", "r_elbow_y", "r_wrist_y"])
frame_idx = 0
while cap.isOpened():
ok, frame = cap.read()
if not ok:
break
result = pose.process(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
if result.pose_landmarks:
lm = result.pose_landmarks.landmark
writer.writerow([
frame_idx,
lm[mp_pose.PoseLandmark.RIGHT_SHOULDER].y,
lm[mp_pose.PoseLandmark.RIGHT_ELBOW].y,
lm[mp_pose.PoseLandmark.RIGHT_WRIST].y,
])
frame_idx += 1
cap.release()書き出したCSVをExcelで開き、ベテラン vs 新人の手首Y座標を時系列でグラフ化するだけで、「動きの溜め」「終端の止め方」の違いが線として見える。これだけで現場の教育ビデオの撮り直し方針が変わる。
Step 5: VLA本格学習はまだ早い
中小規模でPi-0やHelixを自前学習しに行くのは非現実的。データ量、計算資源、実機ロボット、どれも桁が違う。当面は「動作の数値化 + 教育ビデオの自動生成」までで止めるのが現実解だ。それでも教育時間の短縮効果は十分にある(想定値: 新人OJT 3か月 → 6週間)。
Step 6: 採用とのセット設計
最後がいちばん大事で、いちばん飛ばされやすい。
「暗黙知を抜く」だけではROIが回らない。抜いた暗黙知を渡す相手(=新人)が現場にいることが前提だ。ここを忘れて「データ化さえできれば人がいなくても回る」と進めると、ほぼ確実に「データはあるが誰も学べない/活用されない」状態で止まる。
中小製造業の現実解は、AI化と採用を1セットで設計することだ。「データ化された暗黙知を、入ったばかりの新人に最短で渡す」前提でフローを組む。採用チャネルの方も、技能継承の前提に乗ってきてくれる若手をピンポイントで取りに行く必要があるので、製造業特化型の採用支援(bサーチの採善策等)と組み合わせて設計するのが筋がいい。
🌿 人手不足の解決は「採用代行」も選択肢
100種類の採用ツールを組み合わせる採善策(株式会社bサーチ)は無料プランニング実施中・しつこい営業なし。「うちの規模・業種で頼める?」だけでも相談OK。
▶ 100種類の採用ツールを組み合わせた採用代行&無料プランニング実施中【採善策】
![]()
※無料プランニングのみでもOK・期間限定/部分委託も相談可
H2-6. ハマりポイント5つ
実際に手を動かすと、必ず以下のどこかで詰まる。先に列挙しておく。
1. 暗黙知の「言語化できない部分」はやはり残る 日経xTECHの調査記事(2026年)では、製造業の現場担当者の約6割が「AIでも継承不可能な領域はある」と回答している。VLM/VLAで動作差分は出せても、「なぜその瞬間にそう判断したか」の意思決定軸まで抜き切るのは、現状の技術ではまだ難しい。Step 6で書いた「採用とのセット設計」が必須なのは、ここを人間側でカバーする必要があるからだ。
2. 動画データの社外持ち出しが禁止される現場が多い 工場作業映像はNDA絡みで、クラウドLLMへのアップロード自体が禁止される現場が多い。社内LLM(オンプレ Llama系、Gemma系)や、Google Workspace / Microsoft 365のテナント内Geminiで完結させる設計が前提になる。GENIAC採択企業との連携も、データを持ち出さずに済むスキームを最初に握る必要がある。
3. VLAモデルの学習には実機ロボットがないと意味が薄い データだけ集めても、それを動かす実機がなければ「学習用データセット作成代行業」止まりだ。中小製造業がVLAを最終ゴールに置くのは、現時点では筋が悪い。ゴールは「人間の教育」に置くのが現実的。
4. GENIAC採択は「中小製造業向けサービス」とは別物 これがいちばん誤解されやすい。GENIAC第4期は研究開発予算であり、「採択企業に発注すれば中小現場の暗黙知がそのまま抜ける」サービスではない。成果物が業界汎用テンプレートとして降りてくるのは早くて2027年以降。それまで待つのか、Step 1-6で先に動くのか、ここの判断が経営判断としていちばん効く。
5. MediaPipeの骨格抽出は服装と照明に弱い 黒い作業服、油汚れ、暗い工場照明では検出が失敗しやすい。撮影時に補助照明を1台足す、白系の作業着で撮り直す、といった環境整備が事前に要る。
H2-7. 次の一歩
2026年5月時点で打てる手を、立場別に3つに絞る。
A. 経営者/工場長: Step 1-6を社内で誰が回すか決める。最初の1工程・1ベテランで構わない。撮影〜MediaPipe骨格抽出〜LLM差分抽出までを2週間で1サイクル試すと、自社で何が抜けて何が抜けないかが感覚として掴める。並行して、技能継承を前提にした採用設計(bサーチ等)を採用部門と握っておく。
B. 現場エンジニア: MediaPipe + Claude/Gemini動画解析のスクリプトを、社内の1ラインで動かしてみる。サンプルコードはStep 4のもの単体で動く。Claude Codeに「このCSVを使ってベテランと新人の手首軌跡を比較するStreamlitダッシュボードを作って」と投げれば、半日でプロトタイプまで届く。社内導入の伴走支援が必要ならAI鬼管理のような外部パートナーを使うとペースが落ちない。
C. 経営企画: GENIAC第4期の成果物が2027年以降に業界汎用テンプレートとして公開される動きを、ストックマーク陣営とFastLabel陣営の両方でウォッチする。2027年に何が起きるかは現時点では未確定だが、少なくとも「テキスト側」と「身体動作側」の両方で日本標準フォーマットの議論が動き始める。自社データをその標準に乗せる準備(=Step 1-2の撮影とラベル付けだけでも先行)を進めておくと、2027年以降の動きに乗りやすい。
まとめ
| 観点 | ストックマーク陣営 | FastLabel陣営 | 中小ミニマム版 |
|---|---|---|---|
| データ | テキスト・図面 | 動画・骨格・視線 | スマホ動画 + MediaPipe |
| パートナー | 国内16社 | 国内大手自動車OEM | 自社1工程・1ベテラン |
| 予算規模 | 1件最大5億円(GENIAC) | 1件最大5億円(GENIAC) | 想定値5万円以下 |
| 期間 | 2026〜2027 | 2026〜2027 | 2週間/サイクル |
| 出力先 | LLM(テキスト基盤) | VLA(身体動作基盤) | 教育ビデオ + 新人OJT短縮 |
国家予算1件5億円のプロジェクトと、中小現場の5万円ミニマム版は、規模は3桁違うがやっていることの構造は同じだ。撮る、ラベルを付ける、AIに差分を抽出させる、現場へ戻す。
GENIAC第4期は2027年に成果物が降りてくる。それまでの18か月をどう使うかは、各社の判断に委ねられている。少なくとも「待つ」だけで取り戻せる年月ではない。
🤖 ChatGPT/Claude/Geminiを1契約で使い倒す
主要な生成AIを1つの契約で集約できるBtoB SaaS DoraVerse。ChatGPT/Claude/Gemini を都度切り替える手間と、複数サブスク代を一気に削減。14日間無料トライアルあり。
▶ ChatGPTもClaudeもGeminiも。主要AIを実質無料で14日間使い倒すDoraverseトライアル
※月額¥10 USD〜のスタータープランから・年額プランで割引・どこでもリンク対応
🥷 Claude Code を本気で社内導入するなら
「自社の業務を Claude Code で自動化したいが何から手をつけるか分からない」中小製造業向けの伴走型トレーニング AI鬼管理。無料の業務効率化診断 (オンライン面談) で、自社のどこから自動化できるかが見える化される。
▶ AI鬼管理 | Claude Code活用の業務自動化トレーニング 無料診断を予約する
※公式LINE経由でも申込可・診断のみで無理な勧誘なし


コメント