5月14日、経産省が動いた ── GENIAC第4期で起きたこと
2026年5月14日、経済産業省とNEDOは GENIAC第4期 の採択結果を発表した。
製造業データAI-Ready化枠で 9件 (応募36件)、ロボット基盤モデル枠で 2件。前者は1件あたり最大 5億円・100%委託 という重い座組だ。
注目すべきは、この9件のうち 「身体動作の暗黙知」をやる唯一の採択企業 が FastLabel だった点である。
連携先は国内大手自動車OEM。テーマ正式名称は「生産技能者が保有する暗黙知の構造データ化に係る技術開発及び産業汎用性の検証に関する研究開発」。
同日採択された ストックマーク主導案件は国内16社のコンソーシアム で、味の素・伊藤忠・スズキ・三井住友・三菱ケミカル・住友化学・ジェイテクトなどが並ぶ。
ただしストックマーク案件は テキスト・図面・社内ドキュメントの暗黙知 を扱う。
つまりGENIAC第4期は、テキスト軸と身体動作軸という 2つのデータ層を国が同時に押さえた構図 になっている。
この2陣営マップを最初に整理することが、本記事のスタート地点だ。

観点3点 ── この記事で扱う論点はこの3つだけ
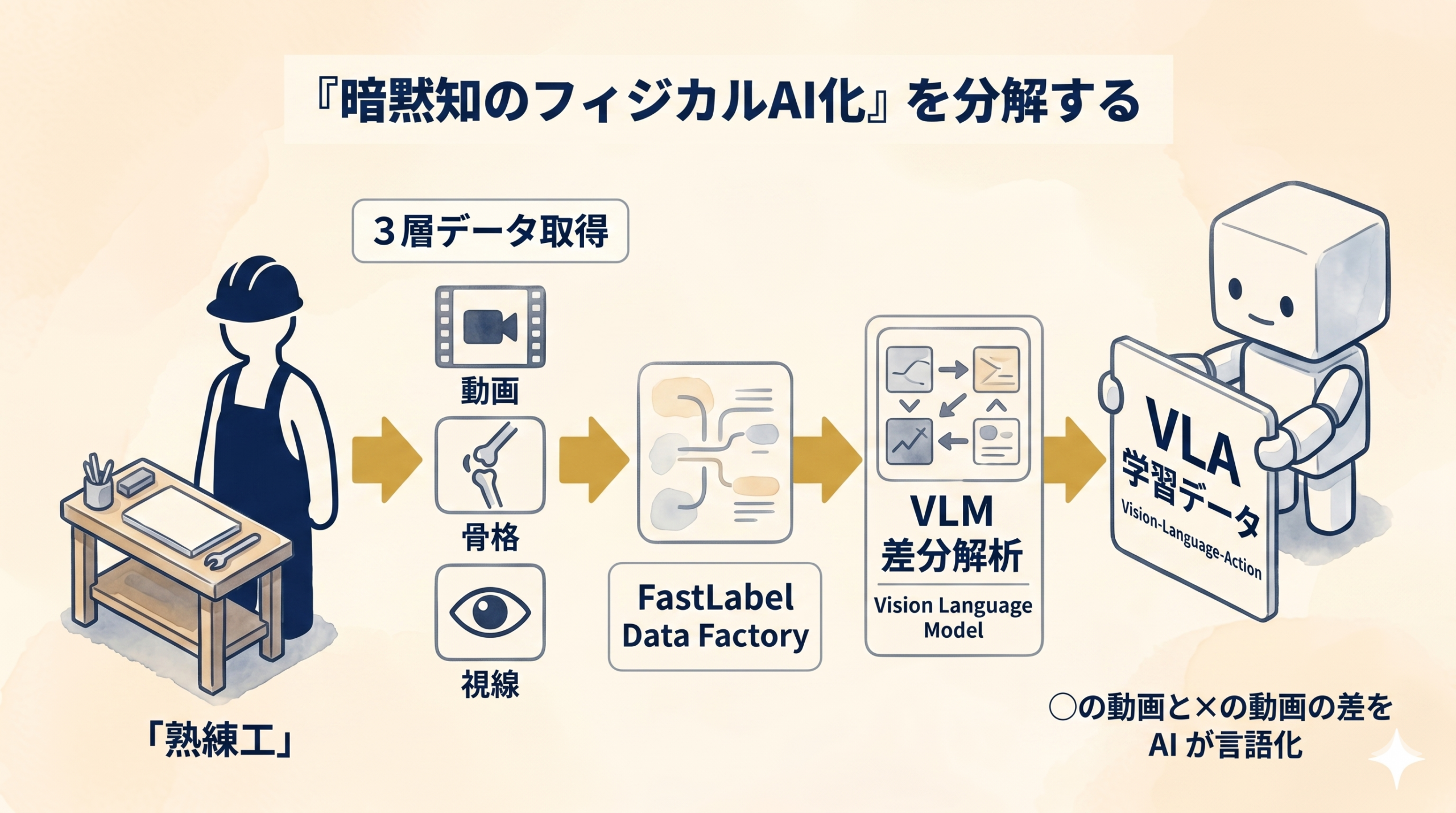
「暗黙知のフィジカルAI化」を分解する (動画 + 骨格 + 視線)
FastLabelが今回扱うデータは大きく3層に分かれる。
| 層 | データ種別 | 取得手段 |
|---|---|---|
| 1 | 工程作業動画 | 一人称 (GoPro / iPhone胸ポケット) と三人称 (三脚) を同時収録 |
| 2 | 骨格モーションデータ | 関節角度・手先軌跡 (MediaPipe / OpenPose系) |
| 3 | 視線データ | アイトラッキングデバイスでの eye-gaze 取得 |
この3層を マルチモーダル・アノテーション で同一タイムラインに揃え、VLM (Vision Language Model) と差分解析で「うまくいった工程」と「いかなかった工程」の違いを自動抽出する。
最終アウトプットは VLAモデル (Vision-Language-Action) の学習用フォーマットだ。
VLAモデルは Physical Intelligence の Pi-0、Figure AI の Helix-02、Figure 02 などに代表される、実世界マルチモーダルデータを大量に必要とする系統である。
既存の OXE データセット (22ロボット527スキル) は 日本工場の「擦り合わせ・面取り・微調整」を含まない。
ここに日本独自のデータ層を作りにいく、というのが今回の戦略軸である。
なぜ国家プロジェクトになったか ── 技能伝承の構造危機
「暗黙知のデータ化」がなぜ国家予算 (1件5億円上限) を割く対象になったのか。
背景は ものづくり白書2025 (2025年5月閣議決定) に集約されている。
| 指標 | 値 | 出典 |
|---|---|---|
| 製造業就業者推移 | 1055万人 → 1046万人 (-9万人) | ものづくり白書2025 |
| 「技能伝承を経営課題」と回答した企業 | 約6割 | ものづくり白書2025 |
| 中小製造業DX未着手率 | 12% (2024年度・前年30%から改善) | ものづくり白書2025 |
未着手率は改善傾向にある。一方で 熟練工がいなくなる速度 はそれを上回るペースで進行している。
構造的な問題なので、個社の努力だけでは詰まる。だから国がデータ層に予算を入れた、というのが今回の文脈である。
上位政策としては、政府の フィジカルAI 5年1兆円 方針 (2026年度予算3,000億円) と、令和8年3月閣議了承のAIロボティクス戦略 がある。
NVIDIA Cosmos / Isaac GR00T などの海外基盤モデルに対し、データ層を日本企業が握る ためのGENIAC枠と理解しておけばいい。
引用ガード: 2022年度値の「能力開発に問題ありとした事業所82.8%」という数字が各種記事で流通しているが、R006 (引用は直近3か月以内) に抵触するため本記事では採用しない。直近データは上記ものづくり白書2025に統一している。
もう一つの陣営 ── ストックマーク16社が示す「テキスト系暗黙知」
GENIAC第4期を読み解く鍵は、FastLabel単体 ではなく ストックマーク陣営との対比 にある。
両者の役割分担を表にすると以下のようになる。
| 観点 | ストックマーク陣営 (16社) | FastLabel陣営 (自動車OEM) |
|---|---|---|
| 扱うデータ | 図面・社内文書・規程・会議録 | 工程動画・骨格・視線 |
| ターゲット暗黙知 | 「設計判断」「業務判断」のテキスト系 | 「身体動作」「微細調整」のフィジカル系 |
| 出口 | 業務LLM・ナレッジ検索 | VLA (Vision-Language-Action) モデル |
| 想定する後工程 | 社内コパイロット・図面検索 | 協働ロボット・人型ロボット制御 |
| 参画形態 | 16社コンソーシアム | OEM1社との深い連携 |
両陣営は対立しているのではなく、日本のフィジカルAIを成立させるための車の両輪 である。
テキスト系の判断ロジックを持つLLMと、身体動作を持つVLAは、最終的には同じ現場で結合される。
GENIAC第4期はその両方に同時に予算を張った、と読むのが妥当だ。

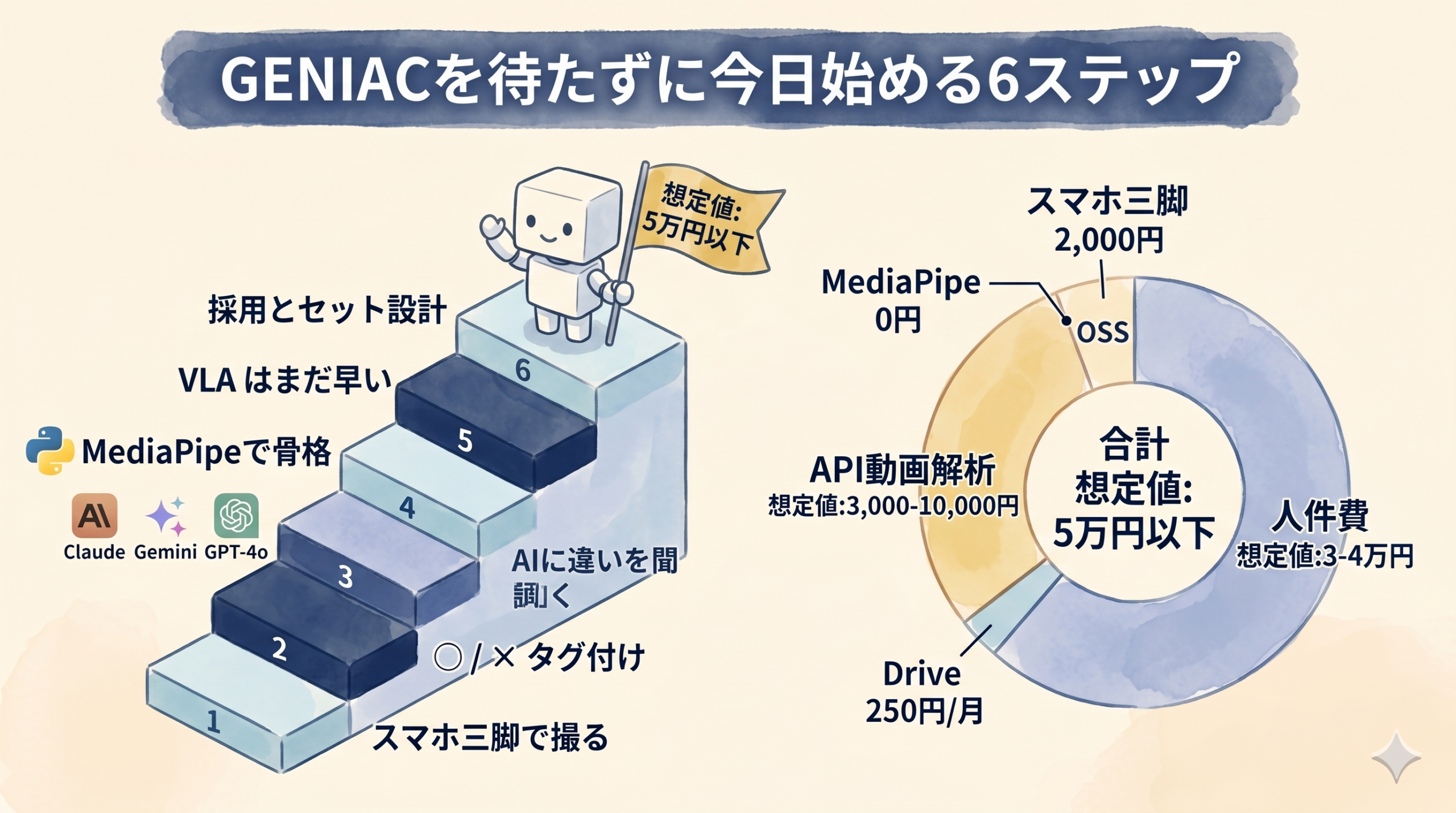
中小製造業がGENIACを待たずに今日始める6ステップ
5億円のプロジェクトが動いているからといって、中小現場が傍観する必要はない。
むしろ GENIAC採択企業がやっていることをミニマムに再現する だけで、技能伝承の出発点には十分立てる。
総コストは 想定値: 5万円以下 に収まる。内訳は後述する。
Step 1. スマホ三脚で熟練工作業を撮る (Day 1〜2)
一人称はiPhoneを胸ポケットや作業帽に固定。三人称は2,000円前後の三脚を作業台斜め前に設置する。
1工程5〜10分 × 10本程度を目安にする。
Step 2. 「○ / ×」だけタグ付け (Day 3)
凝ったアノテーションは要らない。ExcelかNotionで動画ファイル名・結果・一言コメント を残すだけでいい。
20260518_面取り_001.mp4 , ○ , 角の引っかかりなし
20260518_面取り_002.mp4 , × , 角に0.2mmバリ残り
20260518_面取り_003.mp4 , ○ , 上記より速度遅め
この粒度で十分、後段のAIが差を見つけてくれる。
Step 3. AIに動画を見せて「違い」を抽出 (Day 4〜7)
Claude (Sonnet系) / Gemini 2.5系 / GPT-4o の動画対応モデルにアップロードする。
プロンプトは1行で済む。
○の動画と×の動画を比較し、手の位置・速度・順序の違いを箇条書きで挙げてください。
「3秒目で手首が外側に5度傾いている」「工具を握り直すタイミングが異なる」など、
熟練工本人が言語化できなかった差 が言語側から自動的に立ち上がってくる。
ここが最大のレバレッジポイントだ。
Step 4. 骨格抽出はMediaPipeで無料 (Day 8〜14)
Google製の MediaPipe Pose を使えば、Python数十行で関節角度がCSVに落ちる。
import cv2, mediapipe as mp, csv
pose = mp.solutions.pose.Pose()
cap = cv2.VideoCapture("20260518_面取り_001.mp4")
with open("joints_001.csv", "w", newline="") as f:
w = csv.writer(f)
w.writerow(["frame", "right_wrist_x", "right_wrist_y", "right_elbow_angle"])
frame = 0
while cap.isOpened():
ok, img = cap.read()
if not ok: break
res = pose.process(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
if res.pose_landmarks:
lm = res.pose_landmarks.landmark
w.writerow([frame, lm[16].x, lm[16].y, "..."])
frame += 1
CSVをExcelで読み込み、ベテランと新人の手首軌跡を 同じグラフに重ねる だけで、
「ベテランは振り幅が小さい」「新人は終端で減速していない」といった差が目視で分かる。
Step 5. VLA本格学習はまだ早い
ここが冷静さの境目だ。Pi-0 / Helix-02 / Figure 02 系のVLAモデルをローカル再現するのは、中小規模では非現実的 (数千万円〜億コース)。
当面は「動作の数値化 + 教育ビデオ自動生成」までで止めておき、ROIはそこで回収する。
Step 6. 採用とのセット設計
抜いた暗黙知を 誰に渡すか が決まっていないと、データは死蔵される。
新人の入社時研修・中途のオンボーディング・派遣社員の立ち上がりに同時設計する。
これは観点③で詳しく扱う。
コスト内訳 (想定値)
| 項目 | コスト |
|---|---|
| スマホ三脚 | 2,000円 |
| MediaPipe | 0円 (OSS) |
| Claude / Gemini / GPT-4o API 動画解析 (10本想定) | 想定値: 3,000〜10,000円 |
| 動画ストレージ (Google Drive 100GB) | 250円/月 |
| 撮影・タグ付け人件費 (1人20時間) | 想定値: 3〜4万円 |
| 合計 | 想定値: 5万円以下 |
外部にPoCを発注すれば数百万円コースのテーマが、自社内で5万円スタートできる。
ここが本記事で最も伝えたい「真似する側」の立ち位置である。
社内にClaude Codeを持ち込んで動画解析パイプラインを内製したい中小製造業のIT担当向けには、伴走型サービスも存在する。
🥷 Claude Code を本気で社内導入するなら
「自社の業務を Claude Code で自動化したいが何から手をつけるか分からない」中小製造業向けの伴走型トレーニング AI鬼管理。無料の業務効率化診断 (オンライン面談) で、自社のどこから自動化できるかが見える化される。
▶ AI鬼管理 | Claude Code活用の業務自動化トレーニング 無料診断を予約する
※公式LINE経由でも申込可・診断のみで無理な勧誘なし
落とし穴 ── やる前に知っておくべき失敗例7つ
「暗黙知データ化」という言葉は耳ざわりがいい。だからこそ 失敗例を先に並べる 必要がある。
ここでは7つ挙げる。最低どれか1つは自社にも該当するはずだ。
1. マニュアル肥大化症候群
熟練工の技術を細部まで言語化しようとした結果、500ページのマニュアルが完成して誰も読まない。
形式知化の罠としては最も古典的だが、いまだに大半の現場で起きている。
2. 「使われないデータベース」問題
高額なナレッジマネジメントシステムを導入したが、入力する側に動機がなく、参照する側にも検索性がない。
箱だけ立派でデータが入らない のは、技能伝承DXの王道の失敗形である。
3. 動画NDA壁
工場作業映像は 取引先NDAで社外持ち出し禁止 になっているケースが多数派。
クラウドAIに投げる前に、社内ガイドラインの整備と、できれば オンプレ動作するモデル (Llama / Gemma 系) の検討が必要になる。
4. MediaPipe骨格抽出の照明・服装依存
黒い作業服・反射する保護メガネ・暗所の機械加工エリアでは、MediaPipe Pose の検出精度が大幅に落ちる。
撮影時は照明を足す、コントラストのある作業服に変える、複数アングルで撮って欠損を相互補完する、という運用工夫が前提になる。
5. VLA再現非現実トラップ
「Pi-0 を社内で動かしたい」という要望は GPU・データ・MLOps人材すべてが揃って初めて成立する。
中小製造業がいきなりここを目指すと、PoCが空中分解する。Step 5で線を引く理由はここにある。
6. 「GENIAC採択企業に発注すれば暗黙知が抜ける」誤解
FastLabelもストックマークも 基盤技術開発が本業 であり、個別中小企業への請負は前提にしていない。
「採択企業に発注=暗黙知抽出」ではないことは押さえておきたい。
7. 教える時間が削られる連鎖
技能伝承プロジェクトを始めると、熟練者の本業時間が削られて生産効率が落ちる というジレンマが必ず発生する。
撮影は休日や閑散期に寄せる、1日30分まで、といった 時間設計を最初に決めておく のが現実解だ。
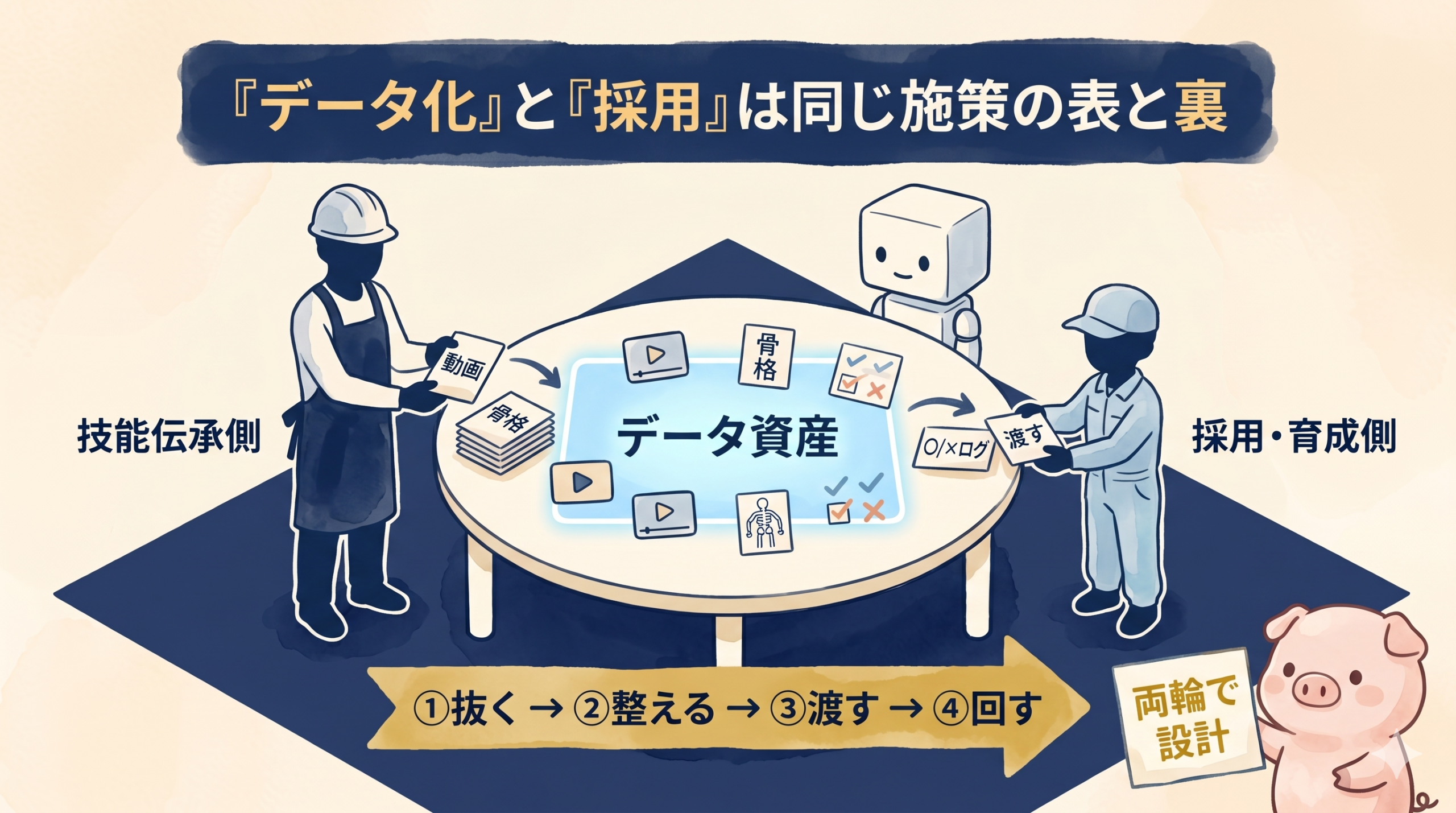
「データ化」と「採用」を分けないという結論
ここまでで技術論は揃った。最後に、観点③に戻る。
暗黙知データ化の出口は 「ベテランがいなくても回る現場」 だが、これは新人や中途が 回す側 に立たない限り意味を持たない。
つまり「技能伝承」と「採用・育成」は 同じ施策の表と裏 である。
| フェーズ | 技能伝承側 | 採用・育成側 |
|---|---|---|
| 1. 抜く | 熟練工の動作を撮影・構造化 | — |
| 2. 整える | AIで「違い」を抽出 | 新人向けにビジュアル教材化 |
| 3. 渡す | データを社内に資産化 | オンボーディング設計に組み込む |
| 4. 回す | データを更新・追加 | 新人が次の熟練工になる導線設計 |
ここで詰まる中小製造業が多い。
「データは抜いたが渡す相手がいない」、あるいは 「人は採ったが渡すデータがない」。
両輪で設計しないと回らないので、技能伝承と採用支援は 同じテーブルで議論する べきテーマである。
採用と暗黙知データ化をセットで設計したいなら、製造業特化の採用支援サービスが入り口になる。
🌿 人手不足の解決は「採用代行」も選択肢
100種類の採用ツールを組み合わせる採善策(株式会社bサーチ)は無料プランニング実施中・しつこい営業なし。「うちの規模・業種で頼める?」だけでも相談OK。
▶ 100種類の採用ツールを組み合わせた採用代行&無料プランニング実施中【採善策】
![]()
※無料プランニングのみでもOK・期間限定/部分委託も相談可
まとめ
| 論点 | 結論 |
|---|---|
| GENIAC第4期で何が起きた | 製造業AI-Ready化9件 + ロボット基盤2件採択、1件最大5億円。データ層への国家投資 |
| 2陣営マップ | ストックマーク (テキスト系・16社) vs FastLabel (身体動作系・自動車OEM) |
| 中小はどう動くか | スマホ + MediaPipe + LLM動画解析で想定値5万円以下から開始可能 |
| 落とし穴 | マニュアル肥大化・データベース死蔵・NDA壁・服装依存・VLA再現非現実・誤解発注・時間削減連鎖の7つ |
| 結論 | 「データ化」と「採用」は同じ施策。分けて設計しない |
GENIAC第4期は2027年までに成果を出すことが求められている。
中小現場が今日から動けば、その成果が公開される頃に 「真似する準備ができている側」 に立てる。
1年半は短いが、スマホ撮影なら今日から始められる。


コメント