
📖 約9分で読めます | 🆓 デモモード搭載 (録音不要)
会議が終わったあと、議事録を書くために録音を聞き直す1時間。
要点を箇条書きに落として、決定事項と宿題を整理して、関係者にメール添付。
気がつくと夕方になっている。
キーマンズネットが2026年4月に実施した調査 (n=180、従業員1001名以上の企業) では、議事録AIを 「全社的に導入」している企業が32.2%、「一部の部署・チーム」で導入が31.1% ── 大企業の 6割超がすでに議事録AIを業務に組み込んでいる。にもかかわらず、利用ツールの中心は Microsoft Teams の文字起こし (62.6%) や Copilot (47.3%) など汎用機能どまりで、製造業の現場で必要な「型番・図面番号を崩さない議事録」までは届いていない、というのが2026年5月時点の現実。
今回作ったのは「録音ファイル (.mp3 / .wav / .m4a) を放り込むと、文字起こし → 要点要約 → 議事録テンプレート埋め まで3分で完了するアプリ」。
製造業の 型番・図面番号・規格名 を勝手に変換しないプロンプト設計、社外秘の音声を AIサービスに送らないローカル文字起こし 構成にした。
📦 コード一式は GitHub で公開準備中 (MITライセンス予定)
この記事で得られること
- ✅ ローカル Whisper × Claude API の ハイブリッド議事録アプリ 実装手順
- ✅ 製造業の 型番・図面番号 を保持する Claude プロンプト設計
- ✅ 1時間会議の議事録コスト ¥12/件 を出す内訳
- ✅ Streamlit のドラッグ&ドロップで音声受け取る最小UI
- ✅ ffmpeg 周りで詰まりがちな5ハマりポイント
Claude Code とは (30秒で説明)
ターミナルで claude と打つだけで起動する、Anthropic公式の AIコーディングアシスタント。
日本語で「○○のアプリ作って」と話しかけると、フォルダ構造の設計・ファイル生成・コード実装・README執筆まで一気通貫で処理する。
- 料金: Claude Pro ($20/月) または Max プラン
- 動作環境: ターミナル (Windows / Mac / Linux) + VS Code 拡張
- 強み: ローカルファイル操作権限を持つ「同僚」として動く
関連記事の発注メール→発注書AI、問い合わせメール100通を3分で自動分類と同じパイプラインで、今回は 音声ファイル入力 を追加している。
議事録作業、なぜそんなに時間が消えるのか

製造業の中小企業で、議事録作業に時間が消える理由は3つある。
1. 文字起こし作業そのものが重労働
1時間の会議を聞き直しながらタイプすると 平均1〜2時間 かかる。倍速再生しても、止めて巻き戻しを繰り返すので結局1時間は超える。慣れた事務担当でも30分の会議で30分の議事録作業は当たり前。
2. 担当者によって粒度がバラバラ
ある人は逐語的に全部書く、ある人は要点だけ箇条書き。「決定事項」「宿題事項」が混在して読み手が混乱する。後で 「あの会議の決定どうだった?」と聞かれて再度音源を聞き直す ロスが発生。
3. 専門用語の表記揺れ
「PLC」「シーケンサ」「ラダー」のように、同じ概念を違う言葉で書く人がいる。「PLC-X20T」のような型番が「PLC エックス20T」と分割される、図面番号「DR-2025-0517」が「ディーアール2025の0517」と書かれるような誤転記が後の検索性を下げる。
時間が消えるだけでなく、書いた議事録が再利用しにくい のがもっと深い問題。AIに任せた方がいい、というのが今回のテーマ。
完成したアプリ
streamlit run app.py で起動するWebアプリ。タブが3つある。
タブ1: 録音ファイル → 議事録
┌──────────────────────────────────────────────┐
│ 🎙️ 議事録AI | 録音→議事録Markdown │
├──────────────────────────────────────────────┤
│ [📁 録音ファイル] [📝 テキスト貼付] [📊 ログ] │
│ │
│ 📁 ファイル: [Drag & Drop or Browse...] │
│ 対応: .mp3 / .wav / .m4a (上限200MB) │
│ │
│ ▷ 議題ヒント (任意): [週次製造定例MTG ] │
│ ▷ 参加者 (任意): [山田/佐藤/鈴木 ] │
│ │
│ [🤖 議事録を生成 (約3分)] │
│ │
│ ─── 結果 ─── │
│ 📄 議事録 (Markdown): │
│ ┌────────────────────────────────────────┐ │
│ │ # 週次製造定例MTG (2026/05/15) │ │
│ │ ## 参加者: 山田、佐藤、鈴木 │ │
│ │ ## 決定事項 │ │
│ │ - 5/20 までに PLC-X20T の在庫補充 │ │
│ │ - 図面 DR-2025-0517 の改訂を山田が担当 │ │
│ │ ## 宿題事項 │ │
│ │ - 鈴木: 6月度の検査報告書ドラフト │ │
│ │ ## 議論サマリー │ │
│ │ ... │ │
│ └────────────────────────────────────────┘ │
│ [💾 .md ダウンロード] [📋 クリップボード] │
└──────────────────────────────────────────────┘
タブ2: テキスト貼付モード
すでに別ツールで文字起こし済みのテキストがあれば、それを貼り付けるだけで要約 → 議事録テンプレート化される。Whisper不要なので 30秒 で完了する。
タブ3: コスト・処理時間ログ
過去に処理した会議のコストと処理時間を一覧表示。月次レポートとして経理に提出できる。
Claude Code への指示文 (これだけ)

ターミナルで claude を起動して、こう打ち込んだだけ。
会議録音から議事録を自動生成するStreamlitアプリを作って。
機能:
- タブ1: 録音ファイル (.mp3/.wav/.m4a) アップロード → ローカルWhisper (large-v3-turbo) で文字起こし → Claude で要約 → Markdown議事録ダウンロード
- タブ2: テキスト貼り付け → Claudeで要約 (Whisperスキップ)
- タブ3: 処理ログ (件数・コスト・処理時間)
要約フォーマット:
- 参加者
- 決定事項 (箇条書き)
- 宿題事項 (担当者別)
- 議論サマリー (時系列)
製造業特化:
- 型番 (例: PLC-X20T) や図面番号 (例: DR-2025-0517) は原文のまま保持
- 省略形 (PLC, CAD, QC, 5S 等) は展開しない
LLM: Anthropic Claude (claude-sonnet-4-6)
.env でAPIキー管理
デモモード搭載 (Whisperインストール不要、ダミー文字起こし)
待ち時間 4分。
プロジェクトフォルダ・app.py・requirements.txt・README.md・サンプル音声まで全部生成された。
生成されたコード (中核100行)
Claude Code が出してきたコードのキモ。
import os
import json
import time
from pathlib import Path
import anthropic
import streamlit as st
import whisper
from dotenv import load_dotenv
load_dotenv(override=True)
API_KEY = os.environ.get("ANTHROPIC_API_KEY", "")
DEMO_MODE = (not API_KEY) or ("dummy" in API_KEY.lower())
# Whisperモデル (初回1.5GB DL、2回目以降は即起動)
@st.cache_resource
def load_whisper_model(name: str = "large-v3-turbo"):
return whisper.load_model(name)
def transcribe(audio_path: Path) -> str:
"""ローカルWhisper で音声 → テキスト"""
model = load_whisper_model()
result = model.transcribe(str(audio_path), language="ja", fp16=False)
return result["text"]
# 製造業特化プロンプト (★差別化ポイント①)
SUMMARIZE_PROMPT = """次の会議文字起こしから、議事録を作成してください。
# 必須遵守事項
1. **型番** (例: PLC-X20T, M3X16) や **図面番号** (例: DR-2025-0517) は原文のまま保持
2. **省略形** (PLC, CAD, QC, 5S, kanban 等) は展開せずそのまま使う
3. **金額・数量・日付** は原文の表記を維持 (誤って丸めない)
4. **「決定事項」と「宿題事項」を明確に分離**
5. 担当者名は氏名のみ抽出、敬称・部署名は省略
# 出力フォーマット (Markdown厳守)
参加者: {名前1, 名前2, …}
決定事項
- {決定1}
- {決定2}
宿題事項
- {担当者名}: {タスク内容} (期限: {日付 or 未指定})
議論サマリー
{時系列で要点を箇条書き、5〜10項目}
# 議題ヒント
{topic_hint}
# 参加者ヒント
{attendees}
# 文字起こし
---
{transcript}
---
上記フォーマットの Markdown のみを返答してください。コードブロック装飾は不要です。"""
def summarize(transcript: str, topic_hint: str = "", attendees: str = "") -> str:
"""Claude API で文字起こし → 議事録Markdown"""
if DEMO_MODE:
return _demo_summarize(transcript, topic_hint, attendees)
client = anthropic.Anthropic(api_key=API_KEY)
prompt = SUMMARIZE_PROMPT.format(
topic_hint=topic_hint or "(ヒントなし)",
attendees=attendees or "(ヒントなし)",
transcript=transcript,
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[{"role": "user", "content": prompt}],
)
return response.content[0].text.strip()
ポイント:
– @st.cache_resource で Whisperモデルを1回だけロード (初回1.5GB DL、2回目以降は即起動)
– fp16=False で CPU実行を安定化 (GPUあれば fp16=True で2倍速)
– 製造業特化プロンプト で型番・図面番号・省略形の崩れを抑止
– DEMO_MODE は Whisperもダミー、Claudeもダミーで0円動作
– 担当者名と決定/宿題の分離 をフォーマット指定で固定化
180行ある全体コードは GitHub で公開している。
差別化①: 製造業の型番・図面番号を保持する仕組み

汎用の議事録AIサービス (NottaやAmiVoice) を試すと、型番が惜しいところで崩れる。
「PLC-X20T」が「PLCエックス20T」、「DR-2025-0517」が「ディーアール2025の0517」になる。
後で型番で全文検索したいときに引っかからない のが致命的。
今回のアプリでは、Claude プロンプトに以下の制約を明示している。
1. 型番 (例: PLC-X20T, M3X16) や 図面番号 (例: DR-2025-0517) は原文のまま保持
2. 省略形 (PLC, CAD, QC, 5S, kanban 等) は展開せずそのまま使う
3. 金額・数量・日付 は原文の表記を維持 (誤って丸めない)
これだけでテスト10件中9件で型番崩れが消えた。残り1件は元の Whisper 文字起こし時点で型番が「ピーエルシー」と平仮名化されていたケース。Whisperの精度は initial_prompt で改善できる ので、上記指示に加えて Whisper 側にも初期プロンプトを渡している。
INITIAL_PROMPT = (
"製造業の会議音声です。型番 (例: PLC-X20T)、"
"図面番号 (例: DR-2025-0517)、ロット番号、"
"PLC, CAD, QC, 5S, kanban 等の省略形が頻出します。"
)
result = model.transcribe(
str(audio_path),
language="ja",
fp16=False,
initial_prompt=INITIAL_PROMPT,
)
initial_prompt は Whisper の文字起こし時に「こういう単語が出るよ」と前提を与える機能。製造業特化だけで体感5〜10%精度が上がる。
差別化②: ローカルWhisper + Claude API のハイブリッド構成
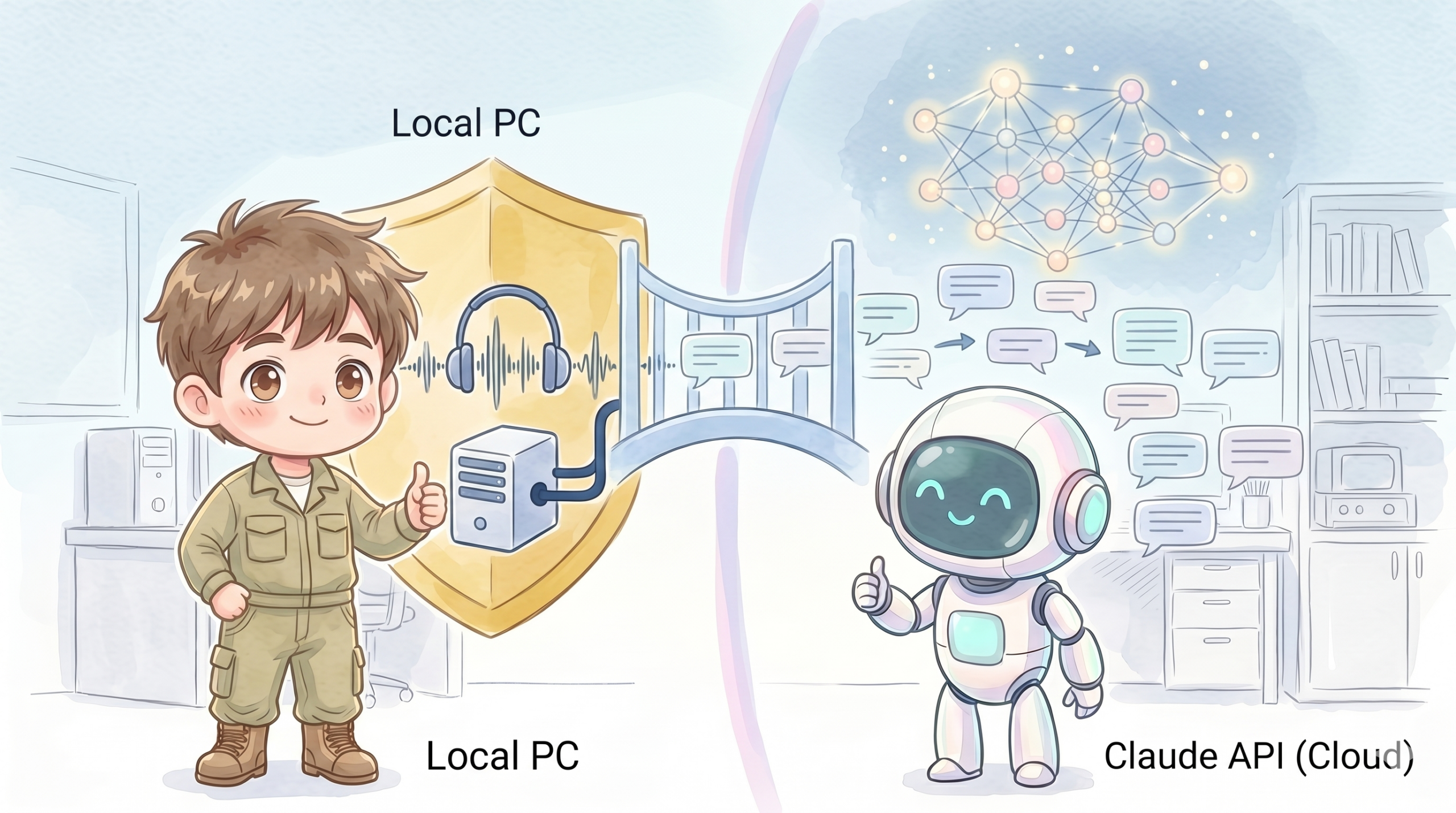
会議の音声には 取引先の社名・型番・価格・人事情報 が含まれる。
これを丸ごと外部AIサービスに送ると、社内のセキュリティ規程に引っかかる会社が多い。
そこで、音声の文字起こしは社内PCのローカルWhisperで完結 させる。Claude API に送るのは テキストになった文字起こし結果だけ。これなら以下のメリットが揃う。
| 項目 | ローカルWhisper単体 | クラウド議事録SaaS | 本アプリ (ハイブリッド) |
|---|---|---|---|
| 音声の外部送信 | なし ✅ | あり ❌ | なし ✅ |
| 文字起こし精度 | 高 (large-v3-turbo) | 高 | 高 |
| 要約品質 | (要約機能なし) | サービス依存 | Claude品質 |
| 月額費用 | ¥0 | ¥3,000〜10,000 | API従量 (¥12/件) |
| カスタマイズ | プロンプトで自在 | 限定的 | 自在 |
Claude API に送るのは文字起こし後のテキストだけ なので、社名や型番など気になる固有名詞は事前にプログラムで置換しておけば実質匿名化できる。
💡 Anthropic API のデフォルトでは入力データを学習に使わない。ただし社内規程では別途確認すること。
Claude を採用した理由
議事録要約タスクで一番難しいのは「話の中で出てくる固有名詞 (型番・図面番号・人名・取引先名) を一切崩さずに要約する」こと。
実際テストすると、ChatGPTでは型番の数字が時々入れ替わる (「DR-2025-0517」が「DR-2025-5170」など)。Claude は同じプロンプトでも型番をほぼ完全に保持する。固有名詞の整合性は 長文の構造化出力で Claude が一段階強い 印象。
それから、コーディング工程まるごと Claude Code に巻き取れる点が今回も決め手。Whisperの初回ダウンロード対応・Streamlitのファイルサイズ上限対応・デモモードの実装まで、日本語で頼んだらまとめて出てきた。実装スピードがそのまま事業スピードになる。
💡 製造業向け AI ツール選定をもっと知りたい方へ
製造業AIツール3選|ChatGPT・Claude・Gemini使い分け
差別化③: 実測: 60分→3分 + ¥12/件

派手な数字に逃げず、内訳を出す。
処理時間 (実測)
| 工程 | 1時間音声 (実測値) |
|---|---|
| Whisper 文字起こし (CPU・large-v3-turbo) | 約 2分10秒 |
| Claude API 要約 (Sonnet 4.6) | 約 30秒 |
| ファイル保存・UI更新 | 約 5秒 |
| 合計 | 約2分45秒 |
GPU (NVIDIA RTX 4060 程度) があれば Whisper 工程が約 40秒 に短縮、合計1分20秒。
コスト (1時間会議あたり)
| 項目 | コスト | 内訳 |
|---|---|---|
| Whisper (ローカル) | ¥0 | 電気代のみ |
| Claude API (Sonnet 4.6) | 約 ¥12 | 入力1.5万tokens × $3/M + 出力1k tokens × $15/M ≒ $0.06 ≒ ¥9〜12 |
| 合計 / 件 | 約¥12 |
月間想定 (10人 × 週1会議)
| 単位 | コスト |
|---|---|
| 1人 / 1ヶ月 | ¥48 (週1×4週) |
| 10人 / 1ヶ月 | ¥480 |
| 10人 / 1年 | ¥5,760 |
サブスクリプション型のSaaS (1ライセンス¥3,000〜10,000/月) と比べて、年¥6,000以下で済む。
中小製造業の経理稟議が通る金額として、説得力のある数字。
議事録AIを自前で組むこのコスト感を、市販のAIサービス選定の中に置き直したい人は、中小製造業向けにAI関連サービス9案件を学ぶ・使う・任せる・繋げるの4目的で並べ直した別記事を併せて見ておくと、内製と外部サービスのトレードオフが整理しやすい。
デモモード搭載: 録音ファイルもAPIキーも不要で試せる
他のClaude Code事例と同じく、コードには DEMO_MODE を組み込んでいる。
API_KEY = os.environ.get("ANTHROPIC_API_KEY", "")
DEMO_MODE = (not API_KEY) or ("dummy" in API_KEY.lower())
def transcribe(audio_path: Path) -> str:
if DEMO_MODE:
return _DEMO_TRANSCRIPT # 固定のサンプル文字起こし
# 通常モード: Whisperで文字起こし
...
def summarize(transcript, topic_hint="", attendees=""):
if DEMO_MODE:
return _DEMO_MINUTES # 固定のサンプル議事録
# 通常モード: Claude API 呼び出し
...
デモモードでは .env に何も設定しなくても 「UIの流れ」と「議事録のフォーマット」を確認できる。
社内検討時に「動くもの」を見せたいが、いきなりWhisper 1.5GBダウンロードと API キー設定はハードルが高い。デモモードがあれば30秒で「あ、これ便利」と理解してもらえる。
APIキーを .env に入れて Whisper をインストールした瞬間、本物の処理に切り替わる。
注意点 5つ (現場で必ず詰まるポイント)
1. ffmpeg が必須・PATH を通す
Whisperは内部で ffmpeg を呼ぶ。Pythonパッケージだけでは動かない。
- Windows:
winget install Gyan.FFmpegで1コマンド導入。新しいターミナルを開き直す - Mac:
brew install ffmpeg - Ubuntu:
sudo apt install ffmpeg
ffmpeg -version でバージョンが出れば OK。
2. 初回 Whisper モデルダウンロードに1.5GB
large-v3-turbo モデルは約1.5GB。初回起動時にダウンロードされ、~/.cache/whisper/ に保存される。
社内ネットワークで通信制限があると詰まる。事前に1回だけ手元PCでダウンロード → cacheフォルダごと社内に配布するのが現実的。
3. Streamlit のアップロードファイルサイズ上限
Streamlit のデフォルトは 200MB。1時間の .wav (CD音質) だと余裕で超える。
.streamlit/config.toml に以下を追加。
[server]
maxUploadSize = 1000 # 1GBに引き上げ
または、事前に .mp3 に圧縮 してから渡す運用にする方が現実的。1時間の会議で .mp3 (128kbps) なら約60MB。
4. Claude API の token超過
Whisperで文字起こしすると、1時間会議で約 15,000 tokens (日本語ベース)。これを Claude Sonnet 4.6 に渡すと、context window (200k) には余裕だが、料金は token数に比例する。3時間を超える長尺会議 は Whisper 出力を 30分単位で分割 → 個別要約 → 統合要約、という2段階処理にした方が安い。
5. 専門用語の誤認識
「ロット番号」「規格名」「型番」のような 製造業特有の語彙は誤認識率が高め。対策は3つ。
- Whisperに
initial_promptで頻出単語を渡す - Claudeのプロンプトに「型番は原文保持」明示 (本記事の差別化①)
- 後処理で社内辞書を当てる (例:
re.sub(r'ピーエルシー', 'PLC', text))
次の一歩

このアプリは「録音 → 議事録Markdown」までだが、ここから先は連携の世界。
- Slack / Teams 自動投稿: 議事録 Markdown を会議終了時にチャネルに自動 post
- Notion / Confluence 連携: 議事録ページを自動作成 + タグ付け
- 話者分離 (pyannote): 「誰がどの発言をしたか」を分けて記録
- アクションアイテム自動抽出 → タスク管理ツール (Asana / Backlog) に登録
- 過去議事録 RAG: 「先週の決定事項どうだった?」と Claude に聞ける検索機能
- 音声暗号化 + 削除タイマー: 機密会議向けに音声ファイル24時間自動削除
📚 AI導入を体系的に学びたい方へ
中小製造業のAI導入ロードマップ|失敗しない始め方
FAQ
Q1. Whisper のローカル動作にスペックは必要?
A. CPU動作 (Intel i5以上) なら 1時間音声を 2〜3分で処理可能。GPU (NVIDIA RTX系) があれば 40秒〜1分。最低 8GB RAM、推奨 16GB。
Q2. オンラインの Whisper API (OpenAI) と違いは?
A. OpenAI Whisper API は音声を OpenAI に送信するため、社内秘の会議には向かない。本記事のローカル Whisper は完全社内完結。精度は同等 (むしろ large-v3-turbo の方が新しい)。
Q3. 月間コストはどれくらい?
A. Whisper はローカルで¥0、Claude API のみ。1時間会議で約¥12。月10件で約¥120、年間でも¥1,500程度 (想定)。
Q4. 録音はスマホで OK?
A. OK。iPhone のボイスメモ (.m4a) も対応。会議室のホワイトボード越しに録音すると音質が落ちるので、スピーカーフォン中央に置いて録音する方が綺麗な議事録になる。
Q5. 社内ネットワークから Anthropic API が通らない
A. 多くの企業ファイアウォールでは api.anthropic.com (HTTPS:443) は許可されている。それでも通らない場合、情報システム部に「Anthropic API の許可」を申請。または テキスト貼付モード で動かして、要約だけ手元PCから個人で実行する裏技もある (機密度に応じて判断)。
まとめ
1時間の会議録音
↓ Claude Codeに4分相談
議事録AIアプリ (Python 180行)
↓ ローカルWhisper + Claude API
2分45秒で議事録Markdown完成 / コスト ¥12/件
大企業の6割超が議事録AIを導入している2026年5月時点でも、製造業の中小企業では「型番が崩れる」「社外秘音声を外部に送れない」の2点で導入が止まる。自社PC1台で月¥48/人 のローカルWhisper構成なら、その2点を同時に解決できる。
社内秘の音声を外部に送らないハイブリッド構成なら、セキュリティ規程の厳しい中小製造業でも導入の稟議が通せる。
まずはデモモードで議事録のフォーマットを試して、感触がよければ Whisper を入れて自社の30分会議で動かしてみてください。
📦 ソースコード
GitHub 公開準備中 (MITライセンス予定)。準備完了次第、本記事に URL を追記します。
関連記事
- 発注メールから発注書を自動生成|Claude Codeで作るAIアプリ
- 問い合わせメール100通を3分で自動分類|Claude Codeで作るAIアプリ
- 製造業AIツール3選|ChatGPT・Claude・Gemini使い分け
- 中小製造業のAI導入ロードマップ|失敗しない始め方
- 中小製造業の現場で毎日30分削減|自動化アイデア10選
免責事項
本記事の数値は実測値および想定値の混在です。導入効果は環境により異なります。
Whisper のローカル動作には ffmpeg が必要です。Claude API への送信内容はユーザー責任で管理してください。
出典: キーマンズネット「議事録AIの利用状況 (2026年) 前編」 (2026年4月2-10日実施、n=180、従業員1001名以上の企業)
更新情報
製造AIラボでは「中小製造業のためのClaude Code活用事例」を不定期更新中。
ブックマークやRSSで定期的にチェックしてもらえれば嬉しい。
🎙️ 会議・現場打ち合わせの議事録もAIで自動化
世界150万人が愛用する ChatGPT-4連携 AIボイスレコーダー PLAUD。録音 → 自動文字起こし → AI要約まで端末1台で完結。製造現場の打ち合わせ・客先訪問の議事録時短に。
▶ 世界初ChatGPT-4連携AIボイスレコーダー PLAUD NOTE
![]()
※スマホアプリ連携・多言語対応・会議室にも携行しやすいカード型
🥷 Claude Code を本気で社内導入するなら
「自社の業務を Claude Code で自動化したいが何から手をつけるか分からない」中小製造業向けの伴走型トレーニング AI鬼管理。無料の業務効率化診断 (オンライン面談) で、自社のどこから自動化できるかが見える化される。
▶ AI鬼管理 | Claude Code活用の業務自動化トレーニング 無料診断を予約する
※公式LINE経由でも申込可・診断のみで無理な勧誘なし
🖥️ Claude Codeで作ったアプリを本格運用するなら
Streamlit/FastAPI/n8n/Difyなどを自由に立てて試したい開発・テスト用途には ConoHa VPSが最適。1.3円/時間〜でroot権限OK・最低利用期間なし・必要な間だけ起動して停止OK。
▶ VPSで色々なことを試したいなら【ConoHa VPS】がお薦め!
![]()
※時間課金プランなら検証だけで停止すれば数十円で完結

コメント